
Data Governance Platforms
Given the importance of data governance it is hardly surprising that there are technologies geared up to help with your efforts. They come in various shapes and sizes with accompanying price tags. In this post we’ll take a look at their general benefits and moving parts to help you decide how they might feature in your implementation.
Why Consider a Data Governance Platform?
Depending on the size of your data governance program, you may find significant benefit from the use of a dedicated data governance platform. Some high-level reasons for implementing a platform to assist with your data governance are outlined below.
Centralised Data Governance Efforts
The platform will provide functionality such as portals, approval workflows and repositories of information around data governance all from one location. This allows for better communication and collaboration across the program and organisational transparency around roles and responsibilities. Governance silos are avoided and universal approaches are more readily available.
Increased Productivity of Regular Tasks
Data governance platforms have various tools to assist with taking the ‘spade work’ out of the program implementation. These are becoming more effective with the addition of AI elements to products.
Complementary Data Management Tools
Your data management efforts will benefit from the various data cataloguing, quality and lineage tools that these platforms provide. In fact your data management team may well have already invested in these tools for just that purpose. Providing these insights in one platform will significantly increase productivity and ‘quality of life’ of data management teams.
When to Implement a Data Governance Platform
 The main purposes of these platforms are to ease the implementation of the data governance program and assist with data management aspects across the estate. Too often however companies will rush out and purchase a platform way too early within the program. The product sits there unused, with a relatively noticeable price tag attached. There is little or no point from a data governance point of view in having a platform without having your strategy, principles, policies and at least some of your processes well defined. To state what is often missed here, wait until you really have things to govern and a need for this platform.
The main purposes of these platforms are to ease the implementation of the data governance program and assist with data management aspects across the estate. Too often however companies will rush out and purchase a platform way too early within the program. The product sits there unused, with a relatively noticeable price tag attached. There is little or no point from a data governance point of view in having a platform without having your strategy, principles, policies and at least some of your processes well defined. To state what is often missed here, wait until you really have things to govern and a need for this platform.
In the meantime gain an understanding of the return on investment of the data governance program through its agreed budget and business capability improvement. Look at how your data governance processes would benefit from the functionality on offer and go through a thorough product selection process. Any vendor selection process can take some time, with their sales teams ordinarily prioritising on reeling in potentially larger prospects. You may also find platform offerings evolving during the process as new tooling and integrations are added.
Functionality and Value-Add
With the above points in mind, there are various areas of functionality that really add to the value of the platform implementation.
Data Quality

This subject area has a well established selection of products that identify, process and improve the quality of data. Some vendors are stronger than others in their offerings here, but the overall functionality they offer can be summed up as:
- Data Profiling for identification of problem areas for data quality efforts
- Data Rectification for assisting with upstream data quality correction, through either direct processing or via data validity reports and exports
- Data Observability to help with operational elements of data quality and related challenges
Where a vendor has an accompanying ETL or data processing toolset these are generally integrated into the above areas. Data observability for example will benefit from greater lineage detail for products that provide this natively to the platform.
Not all vendors leverage the underlying available data processing compute resources for data quality tasks, often offloading to their bespoke data management platform infrastructure. This can prove costly and time consuming when compared to the existing resources such as big data platforms. This aspect of efficient data quality processing should be carefully considered when selecting a suitable platform.
Data Security and Privacy

This critical subject in any data governance program has many touch points and facets to consider. There are numerous ways that your chosen platform can assist with this, with varying functionality in this area across vendors.
Some key items are listed below:
- Definition of roles and assigned personnel
- Identification and classification of data assets for security and privacy considerations
- Auditing of data access, generally from digesting various access logs from data management products and document management systems
Data Transparency
 Awareness of, and access to, data products and assets are key considerations for a successful data governance initiative. Data governance platforms leverage various repositories and portals to assist in data awareness and understanding across the organisation.
Awareness of, and access to, data products and assets are key considerations for a successful data governance initiative. Data governance platforms leverage various repositories and portals to assist in data awareness and understanding across the organisation.
Here are some of the approaches taken:
- Data Catalogues for definitions of data assets and products, business glossaries and approval taxonomies
- Metadata capture of existing data assets through trawlers and scanners that either pull or push metadata from known sources
- Lineage of data assets and products determined from data processing and management operations
- A ‘Data Marketplace’ concept for certifying, publishing and promoting data assets across the organisation
Operational Efficiency
The growing demands on data management teams to help derive business value from data place significant challenges in a growing data landscape. To remain competitive, associated costs and productivity need to be carefully managed. There are a number of benefits that can be gained from a well implemented and populated data governance platform, such as:
- Identification of duplicated processes and data assets
- Monitoring of processing performance and associated resource usage
- Visibility of processes and associated outputs to help derive associated business value
Key Components
The following components are essential to any data governance platform.
Metadata Catalogue
 This is the main repository for metadata and definitions of elements of data management and governance. Centralising this information for transparent access is hugely beneficial in any but the most simplistic of programs.
This is the main repository for metadata and definitions of elements of data management and governance. Centralising this information for transparent access is hugely beneficial in any but the most simplistic of programs.
Most products incorporate the three areas of metadata generally included within data governance, being:
- Operational metadata, providing data provenance, processing and data observability information
- Generally more detailed when coupled with integrated data processing platforms from the same vendor
- Business metadata, such as glossaries, definitions of metrics and other standards
- Technical metadata, describing data assets and their classifications, data sources, transformation mappings and similar structured and semi-structured data definitions
This metadata will be the lifeblood of much of the program information, and can play a significant part in data management simplification through metadata-driven processes. This component should be scrutinised regarding content capability, ease of use and metadata discovery.
Metadata Discovery

Populating the metadata repository in an efficient manner will provide much needed details on the various data assets, sources and related processing that is embedded within various data management products across the organisation.
Population is initiated through the following methods:
- User-initiated discovery requests, targeting a specific source of metadata
- Automated scans via metadata crawler services to collate metadata from various sources
Connectivity to metadata sources varies although most vendors capture the most common cases. The ease with which metadata can be onboarded should be a key consideration with respect to your current and future data estate.
Collaboration Portal

Many programs will use technology such as SharePoint for document collaboration across the program. Some products do have their own portal for hosting the various documents on policies, processes, charters, role definitions and other items of interest to organisational data governance. Either way, a portal for all things data governance is strongly recommended for efficient communication and knowledge sharing.
Extended Components
In addition to the above, many vendors offer additional elements within their data governance suite of products. Depending on your particular priorities these may make the list of ‘must haves’ in your considerations.
Data Access Auditing Services
Data access considerations require no real introduction and are front and centre of any security aware data management team. Many organisations are adopting what is often termed a ‘zero-trust’ approach to data access. This involves closely monitoring privileges to all data sources, and ensuring that data access is tracked through various auditing components. This is particularly challenging given the multitude of data stores that exist in even a modest sized organisation. Document stores are one area that are often overlooked, with the auditing of their access being difficult to achieve without close integration into vendor document store products.
AI Model Management
With increasing use of AI models in companies of all sizes comes associated management challenges. In particular, in light of recent regulatory expectations around suitability of AI and ML outputs for use in business processes, performance of these models is particularly important. Model management tools address the following:
- Understanding model trends and accuracies over time
- Determining computational performance for cost-effective computational resource usage
- Addressing input dataset and model parameter traceability, for reasons such as compliance, privacy and ethics
- Avoidance of bias such as towards demographic groups, particularly regarding protected characteristics such as race, age, disability and sexual orientation, through understanding of model parameter data distributions
Data Quality Engine
Given the generally high priority of data quality within a data governance program, often with considerable value-add attached, this component for many will be promoted to a key constituent. As mentioned above, functionality and implementation varies across vendors and as such should be given careful consideration.
AI Assistance
This can provide considerable productivity benefits for data catalogue-related activities. Categorising and labelling various assets and their attributes according to predefined or newly discovered classifications of data is accomplished through data profiling of samples and applying various matching algorithms. Suggestions on data quality rules based on classifications and attribute types are also easily generated. As you can appreciate, automating these repetitive and time consuming tasks frees up data professionals to apply themselves elsewhere in more specialised activities.
Generative AI
Generative AI tools allow greater assistance beyond the automating of low hanging tasks. Through models focused on the data estate, profiles of organisational data and known applications and outputs, understanding large bodies of information is made considerably simpler. Data discovery challenges such as finding good candidate attributes for customer loyalty indicators are made simpler.
This ability to reason around and through your data improves transparency and productivity. There is less need to to drill into great detail to understand what’s out there. Marketed as the ‘next generation of data governance tools’, these data context-aware assistants are driven by models trained using metadata and data profiling. As they provide more insight and improve on data-related understanding, so their models benefit. More focused and relevant model input further improves accuracy and applicability in a self-learning fashion.
Conclusion
Data governance platforms may prove essential for some organisations in their quest for ‘data governance law and order’. Don’t assume however that you can throw technology at the challenge and sit back.
Without all the other elements we’ve been discussing such as business capability understanding, stakeholder buy-in, strategy, policies and well structured teams the platform will at best be something of a white elephant. The technology decisions should be amongst the last elements to put in place before you grow the program. Only with all other items defined will you truly know what you need from the platform. At this point you can decide on an implementation confident that it will help drive your business capability improvement initiative that is data governance.
Implementing Your Data Governance Solutions
If you’d like to discuss any aspects of your data governance program, whether defining goals, deploying solutions or anywhere in between, please don’t hesitate to get in touch. Our data governance service is a flexible, coworking approach that provides assistance wherever you are on your journey.

Data Governance Frameworks
The implementation of a data governance program involves a number of capabilities and disciplines. We have spoken about key objectives and some common challenges. We’ve also discussed approaches to progressing with the work. Data governance is certainly not new, and as such there are considerable bodies of work that will help with your efforts. For something as involved as data governance, even in smaller organisations, we can look to frameworks to guide our efforts.
In this post we’ll summarise the most common data governance frameworks to help you determine their applicability for your initiative. Their content should be viewed as elements for probable inclusion, with varying priorities across different organisations and business sectors. They may help you determine team structures and will definitely form various implementation areas for backlogs and roadmaps. As we talked about previously, look to roll these out over time based on understanding of requirements, stakeholder priorities and ability to execute.
Summary of Popular Data Governance Frameworks
Provided here is a short summary of each of the featured frameworks and a list of their components to assist you with deciding on which you may want to consider. Each brings their own unique take on the subject. They offer valuable insight into what lies ahead and will help considerably with structuring your approach.
DAMA DMBOK
The DAMA Data Management Body of Knowledge (DMBOK) is available for purchase from DAMA International. As you would expect from DAMA, it is a well structured and detailed resource that is well worth the admission price. At nearly 600 pages, it is an all-inclusive guide to data management. It comprises a data management framework composed of the items below:
- Data Governance
- Data Architecture
- Data Modeling and Design
- Data Storage and Operations
- Data Security
- Data Integration and Interoperability
- Document and Content Management
- Reference and Master Data
- Data Warehousing and Business Intelligence
- Metadata Management
- Data Quality Management
- Big Data and Data Science
© 2017 DAMA International
Data Governance is seen to be the central theme that touches all elements of data management.
The data governance program is further shown as a set of processes and disciplines that surround and influence data management foundational activities and lifecycle management.

These areas will undoubtedly feature to a greater or lesser extent within your own data governance efforts. Each organisation will seek to tailor their efforts according to business need and gaps.
The section on data governance includes steps for implementation as below:
- Assess their current data management maturity
- Identify gaps and areas for improvement
- Develop a roadmap for implementation
- Assign roles and responsibilities
- Provide training and support
- Monitor and measure progress
© 2017 DAMA International
This provides a robust approach to defining and assessing progress of your data governance program against a proven framework. It is a popular choice, being applicable to organisations of varying size. You can find the DAMA DMBOK on Amazon (other booksites are available) or the DAMA International store at https://technicspub.com/dmbok2/.
DAMA also provide images of each of the areas of the framework from the DMBOK for download, available at https://www.dama.org/cpages/dmbok-2-image-download. An example is given below for the data architecture aspects.

The Data Governance Institute Framework
This body exists to provide guidance and expertise on implementing data governance. They have been around for 20 years and offer a huge amount of incredibly insightful material and practical advice around how to succeed in data governance. Their data governance framework moves the focus away from familiar aspects of data management and towards more governance “rules of engagement”. The majority of their articles are free, with a small number of more specialised articles requiring a modest subscription to access. The various components are listed below:
- Mission and Value
- Beneficiaries of Data Governance
- Data Products
- Controls
- Accountabilities
- Decision Rights
- Policy and Rules
- Data Governance Processes, Tools, and Communication
- DG Work Program
- Participants
This is arranged into the framework as shown below.

There are additional articles on aspects such as funding models for data governance, how focus areas may differ in programs, governance models and more. In essence just about every aspect of the initiative is considered. Even if you decide not to use this framework their articles are definitely worth a visit and not at all heavy going.
IBM Data Governance Council Maturity Model
This free resource is focused solely on data governance as a discipline and how to grow this within the organisation. It also uses the concept of a ‘Maturity Model’ to assess capability and track progress. Although only 16 pages it still manages to provide a valuable structure upon which to base your initiative. The concept of data governance is divided into eleven framework elements or ‘domains’, as listed below:
- Organisational Structures and Awareness
- Stewardship
- Policy
- Value Creation
- Data Risk Management and Compliance
- Information Security and Privacy
- Data Architecture
- Data Quality Management
- Classification and Metadata
- Information Lifecycle Management
- Audit Information, Logging and Reporting
Some of these are similar to those within the DAMA DMBOK, although concepts outside data management are also included. These are grouped into functions of Outcomes, Enablers, Core Disciplines and Supporting Disciplines as shown below.
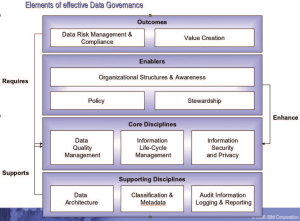
This provides an intuitive view of how elements interact and will assist with planning and prioritising work. When drilling down into the various areas of the model you will however need to consult other more specialised resources to determine implementation details.
CMMI Data Management Maturity Model (DMM) – Discontinued
This is no longer in service, having been discontinued recently. If you are using CMMI approaches to oganisation management you may find aspects that can be applied to data management, however there is no longer a specific model provided.
Implementing a Data Governance Framework
 In the interests of reducing lead-time and delivering value early and often, as previously mentioned in Getting Started with Data Governance an Agile delivery method works well. To recap on the points we previously made, focusing on high-priority items that have a low risk of not being delivered with your work iterations will allow progress in the areas that matter most. If an area is required urgently but is poorly defined, focus on bringing the definition of requirements to a level that allows work to move forward as soon as possible. Once items start being delivered, momentum and enthusiasm will build, helping to drive further value.
In the interests of reducing lead-time and delivering value early and often, as previously mentioned in Getting Started with Data Governance an Agile delivery method works well. To recap on the points we previously made, focusing on high-priority items that have a low risk of not being delivered with your work iterations will allow progress in the areas that matter most. If an area is required urgently but is poorly defined, focus on bringing the definition of requirements to a level that allows work to move forward as soon as possible. Once items start being delivered, momentum and enthusiasm will build, helping to drive further value.
Applying Data Governance in Small to Medium Enterprises (SMEs)
The need for some degree of data governance will be required in organisations wherever data exists, regardless of size. For an organisation owning and processing only a very small amount of ‘low-risk’ data, a smaller program may suffice. A very light touch program prioritising on data security and operations for example may address most concerns. Obviously larger organisations with larger data estates will require more aspects to be covered in greater depth and breadth. It may prove unfeasible to try and cover all aspects of a framework within an SME, however all aspects should be discussed and prioritised accordingly. A reduced framework for initial delivery can then be defined and added to as needed. Items from the DAMA DMBOK worth considering as a first pass for SME data governance frameworks might include:
- Data Governance
- Data Architecture
- Data Storage and Operations
- Data Security
- Data Warehousing and Business Intelligence
- Data Quality Management
You will still want to consider the benefits of establishing a Data Management Office (DMO) and identifying data domains and their respective leaders/owners. The remit of the DMO and the size and number of the data domains will be scaled down but still provide essential functions.
A great reference for considering data governance frameworks for SMEs can be found at https://cornerstone.lib.mnsu.edu/cgi/viewcontent.cgi?article=2125&context=etds, in the form of a thesis submitted for an MSc in Data Science. It also provides a good overview of recent data legislation to be aware of.
Further Reading
The Data Governance Institute has a great round-up of books on data governance.
https://datagovernance.com/bookstore/
In particular “
The DAMA DMBOK website also includes a list of books referenced in the various chapters of the DMBOK. Having them available by chapter makes for another great (although large) browsable list of possible reading material.
https://www.dama.org/cpages/books-referenced-in-dama-dmbok
Summing Up
We hope you found the above overview of data governance frameworks helpful for initiating or progressing your program. Having talked about people and process aspects, we’ll be looking next at data governance technology considerations.
Defining Your Data Governance Initiative
If you’d like guidance and help on any areas of data governance please don’t hesitate to get in touch. Our data governance service is a flexible, coworking approach that provides assistance wherever you are on your journey.

Getting Started with Data Governance
A data governance initiative will involve embedding various practices, processes and standards in a lot of places. The scope of this is generally proportional to the size of your organisation. You will be more successful in scaling this work if you move general activities to departmental or team level resources. This allows you to establish data owners who are close to the data. This will be more productive and risk averse than a central team who are less familiar with the data. With that in mind, let’s look at how we get your data governance started.
Stakeholders
As with any initiative across an organisation, having strong business buy-in is essential for things to gain and maintain momentum. Without this, your data governance program will likely lack acceptance and struggle to add the necessary value expected.
A good start is to identify initial resources and key personnel who will drive progress and set up the communications channels between these parties. These stakeholders must have a vested interest in the overall success of the program. Start with those who are already involved in data architecture, legal aspects of data ownership, and data infrastructure management. They may well already be making noises about what they’d like to see happening which is great. Then, look to the business for those who will really back the program. Those who really appreciate the potential for improving business capabilities through better data governance are ideal. After all business capability improvement is at the heart of every well considered data governance program. Aim for at least as many business people as you have from elsewhere within the organisation as these will help champion the program with the wider audience.
With communications approaches and stakeholders identified you can start working towards formulating the content of the data governance program.
Data Domains
 Your organisational data can be shown to exist within conceptual groupings referred to as ‘data domains’. Your organisation may have already established what these are if you have an enterprise data model or a mature data architecture or modelling practice. They will generally align well to departmental functions, with possible additional core domains such as Customer or Product that may span multiple departments. This should help you think about your structure for delegating and dividing the work across teams. A ‘data domain model’ is a great tool to help you understand how your data can be grouped for governance ownership considerations. Even if it is very high level and boundaries are rather fuzzy this view of your ‘problem space’ will help with the ‘divide and conquer’ mindset.
Your organisational data can be shown to exist within conceptual groupings referred to as ‘data domains’. Your organisation may have already established what these are if you have an enterprise data model or a mature data architecture or modelling practice. They will generally align well to departmental functions, with possible additional core domains such as Customer or Product that may span multiple departments. This should help you think about your structure for delegating and dividing the work across teams. A ‘data domain model’ is a great tool to help you understand how your data can be grouped for governance ownership considerations. Even if it is very high level and boundaries are rather fuzzy this view of your ‘problem space’ will help with the ‘divide and conquer’ mindset.
Being able to conceptualise your data estate into say 10-20 such groups, some of which may underlie a number of others, is invaluable.
You can arrive at a first draft data domain model through one or two workshops with relevant business owners. One technique to help arrive at this is using ‘functional decomposition’ of your organisation to identify business capabilities. These may align well to departmental views depending on the nature of your data. It is advisable is to keep your model high-level, avoiding it morphing into a data integration architecture diagram or similar. You can include ‘subdomains’ to help with the next level of detail, but lower levels will generally not prove beneficial for this exercise. Even in a draft form it will provide a much appreciated guide to understanding your data governance landscape.
Teams and Oversight
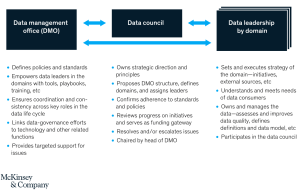
Establishing a team structure that works best for the program is critical to success and productivity. Each organisation will differ in this regard, although there are some common structures that make sense to consider. The following organisational elements are recommended from McKinsey & Company.
©2020 McKinsey & Company
Data Management Office
Although data ownership can be delegated and transferred to domain-based teams, the management of that data is a discipline that will span the organisation. The data management office exists to ensure that all aspects of ownership and processing of data follow established best practices. This may currently informally exist as a group of data architects and data strategists, infrastructure and operations team leads and similar managers.
Data Council
A central guidance authority that oversees the program will generally be required in any initiative on data governance. This data council will sit across all teams, providing consistency and coordination. It also addresses high-level aspects of the program, such as funding and issue escalation. It may include key stakeholders from the business as well as heads of data such as the Chief Data Officer (CDO) or Chief Information Officer (CIO) and related legal officers. The Chair of the council may be the head of the data management office, although having a senior business figure as chair will work better if business backing needs to be improved.
Domain Teams
How you structure your delivery teams is going to depend on various factors, including organisational culture and existing structures. You may decide on some central teams that provide supporting roles, and then further teams that address data domains. You may instead structure your teams around the different key objectives we talked about in an earlier post Data Governance Objectives and Challenges, such as legal, security etc. although this can detract from a business value driven program. With data domain teams established that are supported by specialist teams you are able to focus on meeting governance requirements that align to business data processes.
Strategy
Principles
Before you can really start to determine what to include, you’ll need a set of principles on which to base your program. Just saying ‘doing data governance’ isn’t going to get you far when it comes to formulating priorities and content later on. You should be looking to add new business capabilities through the actions of the program, thereby ensuring business value. A great way to determine a strategy, as suggested by John Ladley in his book on Data Governance is to list the principles that are basically answering the question ‘What are we trying to achieve?’ in applying data governance to your organisation. In our previous post we talked about ‘Key Data Governance Objectives’ and these should help guide you here. These principles may be relatively common ones, such as ‘Data/Information Quality’ and ‘Risk Management’, or they may be more aligned with a particular aspect of the organisation that needs addressing. They should serve to guide thinking and help justify courses of action.
Policies
From your handful of principles you can then look as determining policies to essentially reinforce and realise these. These policies then form a backbone for commonality across business areas and ensure consistency and quality throughout the program with minimal concern for deviation. As with many aspects of the program, these will evolve over time, but having a good set of core policies in place helps add structure and guidance to initial efforts.
Requirements Gathering
 There are some great reference materials on what constitutes data governance and how to go about formulating a program, as we discuss in a later post on Data Governance Frameworks. Once you understand the key constituents, decide with your stakeholders on the relative priorities.
There are some great reference materials on what constitutes data governance and how to go about formulating a program, as we discuss in a later post on Data Governance Frameworks. Once you understand the key constituents, decide with your stakeholders on the relative priorities.
Some organisations may try and determine an all encompassing plan from day one. As well as being a truly overwhelming task this ‘all requirements upfront’ approach will involve significant rework and ‘planning churn’. This may be familiar to those taking a ‘Waterfall’ approach to implementation. Stakeholders may understandably be less than happy with the increase lead time and reduced productivity and value resulting from this.
Agile Requirements Management
Those familiar with Agile software development understand how this approach tends to cut waste and keep requirements relevant. Let’s take a look the benefits of an Agile approach to data governance requirements management.
Why Agile?
One key advantage to an Agile approach is that on each cycle of work the priorities and risks to successful implementation are revisited. The high priority work with the best chance of getting implemented during that cycle is given preference. Those elements that have requirements that are less well defined or understood are refined based on priority. Details are gathered to understand enough to reach a level where the risk to implementation is acceptably low. By defining the details only when the items are confirmed as needed we avoid thrashing out details too early. This avoids those items that may turn out to not actually be required or have changed requirements. Waste and lead time are reduced and items are prioritised and delivered as required. This approach has real benefits with regard to progress, maintaining momentum and generally delivering value early and as needed.
The ‘Agile mindset’ may however be something that exists only within development teams within the organisation if at all. As such if this approach is to be employed there may be a need to ‘win over’ or at least explain the benefits of this way of working.
Determining Your Agile ‘Epics’
 If you do decide to work in an Agile fashion, when starting your backlog of Epics, bear in mind that despite the name these Epics shouldn’t be huge. Taking each of the objectives in our previous article Data Governance Objectives and Challenges as an Epic would probably be too broad. You could however arrive at a number of Epics within each of these areas, also having ones that span these objectives. Some of your Epics may be foundational items that are required before you can build further, such as establishing a communication approach for the program, or determining a high-level data domain model.
If you do decide to work in an Agile fashion, when starting your backlog of Epics, bear in mind that despite the name these Epics shouldn’t be huge. Taking each of the objectives in our previous article Data Governance Objectives and Challenges as an Epic would probably be too broad. You could however arrive at a number of Epics within each of these areas, also having ones that span these objectives. Some of your Epics may be foundational items that are required before you can build further, such as establishing a communication approach for the program, or determining a high-level data domain model.
It is relatively easy to determine initial high level ‘Epics’ on the key areas of the program. These are then drilled into to provide a number of ‘Features’ that will form the functional elements of the program. The backlog of these items will evolve and expand over the course of the program. Changes in regulation, security, and internal demands for data will direct the workload over time. This is the nature of the program of work and working Agile will complement this shifting nature. Once you have agreed some of the details for these backlog items you will be able to get your data governance initiative started.
Conclusion
Embarking on your data governance journey doesn’t have to be a planning behemoth or feel like herding cats. With a small group of stakeholders and understanding of how your data estate needs to relate to the business you can start the ball rolling. Agile practices will help to provide value early and prove to the organisation that data governance works at all levels. As we continue this series, we’ll take a brief look at some of the frameworks and technologies that can help you achieve your goals.
Moving You Forward with Data Governance
If you’d like to understand more about getting started with data governance please don’t hesitate to get in touch. Our data governance service is a flexible, coworking approach that provides assistance wherever you are on your journey.

Data Governance Objectives and Challenges
In our previous post What is Data Governance? we discussed the basics of data governance and how it has progressed from its original remit of ‘Compliance and Security’ to a more rounded, user-centric definition. Getting data governance moving in the right direction in any organisation is important more so now than ever. In this post we’ll take a look at some of the key objectives and challenges involved.
Key Data Governance Objectives
Business Capability Improvement
If there is one phrase that sums up the overall reason for embracing data governance, this is probably it. If you’re not improving the business’s ability to do what is beneficial financially, either directly or indirectly, then people will question the whole point of the program. So with that in mind, what are we setting out to do and why?
There are a number of key areas that define what we are aiming to achieve with our data governance initiative. These can be formalised into a program strategy statement, as we’ll discuss later in the series. A suggestion on how to group your efforts is given below.
Compliance
Data regulation is gathering pace amidst criticism for having been lacking in the past. Organisations will need to be conversant with more laws and consequences of drifting from their responsibilities in these regards. Adhering to relevant laws and regulations regarding data privacy and protection is critical. The need to involve legally qualified personnel in this area is not to be underestimated. Greater investment in this area is required in certain industries such as Health Care and Finance.
Data Security and Sensitivity
The need to protect data from unauthorised access or breaches is a point that needs no preamble. What is often missed however is not just the threat from external parties but also that internally. There is a need to understand how internal use and misuse of data can have an impact. The identification and correct handling, retention and disposal of sensitive data is a particularly challenging issue.
Data Quality Improvement
Ensuring that data is accurate, timely, consistent, reliable and complete are just some of the drivers in establishing data trust. The old adage ‘garbage In – garbage out’ is never truer than in this area. Making data quality a key objective will add considerable value to your efforts in data governance.
Operational Efficiency
Streamlining data management processes will improve efficiency and reduce costs. Various aspects of data architecture will determine the degree to which these efficiencies will be achievable. Identification of unwanted duplication of data, redundant or legacy processing and other undesirable elements of the data management activities within the organisation are essential. Data Observability also plays a part here, allowing for identification of issues with data processing. This allows proactive management of the data workloads and corrective actions when required.
Decision-Making Support
Data analytics and business intelligence activities all benefit from the efforts made in data governance. Providing data consumers with accessible, trustworthy data is a key data governance objective. This is essential for supporting strategic business decisions.
Data Governance Challenges to Success
There are a number of key challenges generally encountered when attempting to implement a robust data governance program. These vary in degree based on factors such as industry, organisation size, data manageability and the general opinion towards such an undertaking. Each organisation’s efforts will meet with their own unique bumps in the road of course, however being mindful of common issues encountered helps navigate a path to success.
Cultural Resistance
 The nature of data governance is an organisation-wide mindset to data in general, and will involve establishing processes and assigning responsibilities. If there is no clear understanding of the benefits of the program, it risks being perceived as ‘just more hassle’ or ‘more forms to fill’. These negative connotations attached to the program from the start can be hard to remove. Make sure to send a clear message about the objectives and real benefits to data consumers that will result before moving to implement any changes.
The nature of data governance is an organisation-wide mindset to data in general, and will involve establishing processes and assigning responsibilities. If there is no clear understanding of the benefits of the program, it risks being perceived as ‘just more hassle’ or ‘more forms to fill’. These negative connotations attached to the program from the start can be hard to remove. Make sure to send a clear message about the objectives and real benefits to data consumers that will result before moving to implement any changes.
Perceived Value
Given the varying degree of appreciation for a data governance program that will inevitably exist, there will be accompanying differences in opinion on its relevance. Look to appoint stakeholders who understand the real benefits of the program. These help champion the message within the organisation that data governance is not some ‘necessary evil’ or ‘something that just has to be done’. They can promote the benefits to all, either directly or indirectly that delivering on the objectives will bring. If a financial perspective on the benefits is required, this can be relatively easily achieved. Simple discussions around productivity aspects and risk mitigation will yield an appreciation of monetary value. It is advisable to assess early on the value the program will provide in empowering your data professionals. This ‘data value-add’ is often overlooked in favour of reducing risk from non-compliance and security concerns. All these benefits should be included when promoting the endeavour.
Inadequate Resourcing
 Another key issue often faced when rolling out elements of data governance is the lack of understanding of the resourcing required. Often data ownership and stewardship duties are dropped unceremoniously into the laps of already overloaded or stretched managerial staff who are given few pointers on what their new additional role as ‘data owner’ or ‘data custodian’ or ‘data access approver’ really entails. The requisite amount of resource needs to be available if the role is to be done correctly. Failure to address this results in inevitable pushback, disengagement or mistakes due to overloading. Make allowances in workloads for induction, training, and execution of these new responsibilities.
Another key issue often faced when rolling out elements of data governance is the lack of understanding of the resourcing required. Often data ownership and stewardship duties are dropped unceremoniously into the laps of already overloaded or stretched managerial staff who are given few pointers on what their new additional role as ‘data owner’ or ‘data custodian’ or ‘data access approver’ really entails. The requisite amount of resource needs to be available if the role is to be done correctly. Failure to address this results in inevitable pushback, disengagement or mistakes due to overloading. Make allowances in workloads for induction, training, and execution of these new responsibilities.
Communication
 A data governance program involves a lot of work which can be shared over a wide pool of resources. It is paramount to ensure clear and succinct communication streams are established as more people become involved. Large numbers of meetings discussing standards and policies with a lot of silent attendees is not the best use of time. A portal for sharing knowledge, together with chat platform channels is a much more efficient and flexible means of keeping everyone in the loop for developments and announcements. This frees people up to fit in their responsibilities around other work.
A data governance program involves a lot of work which can be shared over a wide pool of resources. It is paramount to ensure clear and succinct communication streams are established as more people become involved. Large numbers of meetings discussing standards and policies with a lot of silent attendees is not the best use of time. A portal for sharing knowledge, together with chat platform channels is a much more efficient and flexible means of keeping everyone in the loop for developments and announcements. This frees people up to fit in their responsibilities around other work.
Documentation
There will undoubtedly be terms and concepts that some of those involved will not be familiar with. The usual rules apply about introducing these concepts and having glossaries and reference material to ease any learning curve. Establish a portal as the official source of information at the very start of the program. The structure of the documentation store will probably need to flex as things progress. Put in place a few foundational elements together with an approval process for content publishing. This will help ensure that things maintain an agreed structure and quality and tone of content. Encourage submissions from those within the program who will have skills and knowledge that will assist with these. Do not reinvent the wheel here however. There are a huge number of resources already out there to help with data governance in the form of frameworks, which we discuss in our series post Data Governance Frameworks.
Perceived Scale
 Often the perceived scale of the program can introduce issues with initiating and motivating those involved. It can appear to be a monumental undertaking ahead. For those directly tasked with getting things moving it is understandably a daunting prospect. Look at the work as a collection of high and lower priority tasks that can be spread over time and across teams. This is obviously preferable to a Sisyphean task for a central team. Resource your efforts accordingly, possibly looking for bringing in external subject matter experts where required. If you have managed to arrive at some ‘ballpark’ figure for the tangible benefits of the program this will help in determining your budget over time and allow you to invest accordingly.
Often the perceived scale of the program can introduce issues with initiating and motivating those involved. It can appear to be a monumental undertaking ahead. For those directly tasked with getting things moving it is understandably a daunting prospect. Look at the work as a collection of high and lower priority tasks that can be spread over time and across teams. This is obviously preferable to a Sisyphean task for a central team. Resource your efforts accordingly, possibly looking for bringing in external subject matter experts where required. If you have managed to arrive at some ‘ballpark’ figure for the tangible benefits of the program this will help in determining your budget over time and allow you to invest accordingly.
Data Architectures
 Depending on the maturity of your data architecture capabilities, you may face additional challenges from a data management perspective. You may be fortunate enough to have a well planned, future-proof and data consumer-focused landscape. It may provide good transparency and purpose to your various data assets. You may have arrived at a more ‘accidental architecture’. This will not be as well structured but is still functional and serves a need. Perhaps you are undergoing a ‘Digital Transformation’ initiative and things are very much in flux in this area.
Depending on the maturity of your data architecture capabilities, you may face additional challenges from a data management perspective. You may be fortunate enough to have a well planned, future-proof and data consumer-focused landscape. It may provide good transparency and purpose to your various data assets. You may have arrived at a more ‘accidental architecture’. This will not be as well structured but is still functional and serves a need. Perhaps you are undergoing a ‘Digital Transformation’ initiative and things are very much in flux in this area.
The relative complexity, transparency and stability of your data estate will have a direct influence on how you address various objectives. Data Management and Data Security and Sensitivity will require additional focus in more complex environments. These challenges are not unsurmountable with the help of data governance and data management products and platforms. You may want to implement these to a greater or lesser degree as part of the program. We’ll touch on some of these solutions later in the series.
Evolving Regulations
As mentioned, data regulations are playing catchup. As such there will be a lot of movement in this area as more authorities weigh in, flex their powers and test the mood. If you are late to the game it may take time to get up to speed. Divide the tasks and prioritise, getting external suppliers in where expert resources are not available in-house.
Next Steps
Hopefully this article has given you a reasonable idea of what lies ahead whilst providing you with some points to be aware of when starting your data governance endeavour. In the next article we’ll discuss ways of working to start achieving our objectives.
Ready to Overcome Your Data Governance Challenges?
If you’d like to talk to someone about how to move forward with an effective data governance initiative please don’t hesitate to get in touch. Our data governance service is a flexible, coworking approach that provides assistance wherever you are on your journey.

What is Data Governance?
Data governance is a discipline that exists to ensure the effective, efficient and responsible use of information to allow an organisation to achieve its goals. It is a subject that encompasses the practices, processes, standards, and metrics required in meeting this challenge. Not surprisingly, it can be quite an imposing and at times foreboding subject, conjuring up images of red tape, bureaucracy and obstacles for those who work in data. Data governance does however exist for the benefit of all. Despite common perceptions to the contrary, its real purpose is not to complicate matters. Its aims are to provide a structured framework for managing data assets across an organisation, ensuring that data is accurate, available, consistent, and secure.
At its core, data governance involves the coordination of people, processes, and technology to manage, protect and capitalise on data assets. The practice defines who can take what action, upon what data, in what situations, using what methods. It’s a critical component of an organisational data strategy, including data quality, data management and policies, as well as aspects of business process management and risk management. With all this in mind, given the importance of data to just about every organisation, data governance is not something that can really be kicked down the road for too long.
Traditional Top-Down Data Governance
 Historically, data governance has been a top-down initiative. The ‘command and control’ approach and accompanying rules are often perceived by those subject to them as obstructive and arduous. For a long time, data governance was about compliance and data security only. Both these are of course incredibly important to any organisation working with data, with reputations being frequently thrown to the wall in their absence. Organisations of all sizes often make mistakes in these areas as we are all aware of with regular media coverage of breaches and abuse of rules around customer/user data. There is however much more to the remit of what we now refer to as data governance.
Historically, data governance has been a top-down initiative. The ‘command and control’ approach and accompanying rules are often perceived by those subject to them as obstructive and arduous. For a long time, data governance was about compliance and data security only. Both these are of course incredibly important to any organisation working with data, with reputations being frequently thrown to the wall in their absence. Organisations of all sizes often make mistakes in these areas as we are all aware of with regular media coverage of breaches and abuse of rules around customer/user data. There is however much more to the remit of what we now refer to as data governance.
Modern Bottom-Up Data Governance
A more recent view of data governance includes more elements that are focused on the benefits to employees who work with data. Any data consumers from business analysts and C-suite executives to data engineers and data scientists could be said to have the same fundamental needs of their data. If they are to capitalise on the potential of their data it needs to be trustworthy, adaptable, well understood and available. This is in essence what makes data valuable. If any of these are lacking, the value decreases as the consumers of that data wrestle with the issues that result.
 More and more data is being consumed by businesses who also seek more agility in working with it. This moves the responsibilities and ownership to the early stages of this data’s journey within the organisation. ‘Self-service’ data analytics brings greater freedom to work with data at a departmental level. This requires a shift of responsibility regarding the ownership of that data. If data governance is to scale to satisfy the modern organisation’s appetite for data, there will be a need to extend it beyond the traditional central team of stewards and steering committees. The onus should be broadened to include data subject owners at the departmental level, or perhaps even lower. The role of central organisational elements of the program are still critical in defining company-wide requirements and standards. They are however only part of the whole program, serving a number of roles that generally do not require an intimate understanding of business data.
More and more data is being consumed by businesses who also seek more agility in working with it. This moves the responsibilities and ownership to the early stages of this data’s journey within the organisation. ‘Self-service’ data analytics brings greater freedom to work with data at a departmental level. This requires a shift of responsibility regarding the ownership of that data. If data governance is to scale to satisfy the modern organisation’s appetite for data, there will be a need to extend it beyond the traditional central team of stewards and steering committees. The onus should be broadened to include data subject owners at the departmental level, or perhaps even lower. The role of central organisational elements of the program are still critical in defining company-wide requirements and standards. They are however only part of the whole program, serving a number of roles that generally do not require an intimate understanding of business data.
Key Components of Data Governance
There are differing opinions on what really ‘defines’ a data governance program. A good starting list that covers most aspects is given below:
Data Quality
This focuses on ensuring that data is accurate, complete, and reliable. If data is to be trusted, this is a key aspect of building that trust.
Data Management
The processes and policies for handling data throughout its lifecycle. Data should be well managed, shaped to fit the consumer, and provided for consumption. Ease of use and availability are key considerations. This is traditionally where organisations will invest a large part of their resources in data engineers and systems administrators. To complement these, there needs to be the understanding of cataloguing, describing and communicating these data assets across the organisation.
Data Policies
The rules and regulations that govern data usage within an organisation. These traditional elements aren’t going away and form the bedrock on which teams can build their own initiatives. From there they can expand upon and decentralise responsibility for data ownership.
Business Process Management
Aligns data governance with business processes to ensure that data supports business objectives and capabilities. The true value in data is in providing the insight and understanding required by the business to be successful. This alignment of the ‘behaviour of data’ within a business with the various drivers of success is essential more today than ever. Careful consideration is required throughout all aspects of an organisation’s operations. All areas are fueled by the availability of the right data, from logistics to marketing and beyond. If the flow of that data is stifled, so too are the opportunities within the business.
Risk Management
Identifies and mitigates risks related to data privacy, security, and compliance. The risks associated with an organisation’s data are reduced only by having a firm understanding of this information. Where it resides, what it includes, how it is being accessed and how is should be safeguarded are all paramount. Penalties for not managing this risk are not just financial in the form of hefty fines but perhaps more damagingly reputational. Customers have suffered a slew of data breaches and misappropriation of their data over the last decade or so. Organisations need to do more to address these very real concerns.
The above components highlight key drivers behind programs on data governance. For more formal and in-depth definitions there are various frameworks available. We’ll discuss in our series post Data Governance Frameworks.
Summing Up
We are all very aware of the rapid increase in the need for data and its importance within the organisation. The availability of affordable platforms for generating value have placed data front and centre of businesses of all sizes. Given the perceived overhead of the list above it is no surprise that many organisations are late to the game. Forming a robust data governance program or discipline is an involved undertaking. However, for those that truly understand the value of their data and the responsibilities of ownership, data governance is a subject that should be embedded in all areas of the business.
During this series we’ll be taking a look at some of the challenges of data governance. We’ll also discuss strategies and approaches for overcoming what may at first appear to be a Herculean task. Once we understand the art of the possible we will then discuss how this can be employed to maximise business benefit.
Helping You Apply Effective Data Governance
If you’d like to understand more about data governance don’t hesitate to get in touch. Our data governance service is a flexible, coworking approach that provides assistance wherever you are on your journey.

Data Governance
In our latest blog series, this time on the contemporary subject of data governance, we’ll be taking a look at what it is, why it matters, and how to get moving with an organisational program.
We’ll also take a look at various frameworks and technologies that will help you understand what the undertaking involves and how to really focus on the benefits to your business.
First up, let’s take a look at what we mean by data governance.

The Hive MetaStore and Local Development
In this next post in our series focussing on Databricks development, we’ll look at how to create our own Hive metastore locally using SQL Server, and wire it up for the use of our development environment. Along the way we’ll dip into a few challenges with getting this running with your own projects and how to overcome them. This should provide us with our final element of our local Spark environment for Databricks development.
The Hive Metastore
Part of the larger Apache Hive data warehouse platform, the Hive metastore is a repository for details relating to Hive databases and their objects. It is adopted by Spark as the solution for storage of metadata regarding tables, databases and their related properties. An essential element of Spark, it is worth getting to know this better so that it can be safeguarded and leveraged for development appropriately.
Hosting the Hive Metastore
The default implementation of the Hive metastore in Apache Spark uses Apache Derby for its database persistence. This is available with no configuration required but is limited to only one Spark session at any time for the purposes of metadata storage. This obviously makes it unsuitable for use in multi-user environments, such as when shared on a development team or used in Production. For these implementations Spark platform providers opt for more robust multi-user ACID-compliant relational database product for hosting the metastore. Databricks opts for Azure SQL Database or MySQL and provides this preconfigured for your workspace as part of the PaaS offering.
Hive supports hosting the metastore on Apache Derby, Microsoft SQL Server, MySQL, Oracle and PostgreSQL.
SQL Server Implementation
For our local development purposes, we’ll walk through hosting the metastore on Microsoft SQL Server Developer edition. I won’t be covering the installation of SQL Server as part of this post as we’ve got plenty to be blabbering on about without that. Please refer to the Microsoft Documentation or the multitude of articles via Google for downloading and installing the developer edition (no licence required).
Thrift Server
Hive uses a service called HiveServer for remote clients to submit requests to Hive. Using Apache Thrift protocols to handle queries using a variety of programming languages, it is generally known as the Thrift Server. We’ll need to make sure that we can connect to this in order for our metastore to function, even though we may be connecting on the same machine.
Hive Code Base within Spark
Spark includes the required Hive jars in the \jars directory of your Spark install, so you won’t need to install Hive separately. We will however need to take a look at a few of the files provided in the Hive code base to help with configuring Spark with the metastore.
Creating the Hive Metastore Database
It is worth mentioning at this point that, unlike Spark, there is no Windows version of Hive available. We could look to running via Cygwin or Windows Subsystem for Linux (WSL) but we don’t actually need to be running Hive standalone so no need. We will be creating a metastore database on a local instance of SQL Server and pointing Spark to this as our metadata repository. Spark will use its Hive jars and the configurations we provide and everything will play nicely together.
The Hive Metastore SchemaTool
Within the Hive code base there is a tool to assist with creating and updating of the Hive metastore, known as the ‘SchemaTool‘. This command line utility basically executes the required database scripts for a specified target database platform. The result is a metastore database with all the objects needed by Hive to track the necessary metadata. For our purposes of creating the metastore database we can simply take the SQL Server script and execute it against a database that we have created as our metastore. The SchemaTool application does also provide some functionality around updating of schemas between Hive versions, but we can handle that with some judicious use of the provided update scripts should the need arise at a later date.
We’ll be using the MSSQL scripts for creating the metastore database, which are available at:
https://github.com/apache/hive/tree/master/metastore/scripts/upgrade/mssql
In particular, the file hive-schema-2.3.0.mssql.sql which will create a version 2.3.0 metastore on Microsoft SQL Server.
Create the database
Okay first things first, we need a database. We also need a user with the required permissions on the database. It would also be nice to have a schema for holding all the created objects. This helps with transparency around what the objects relate to, should we decide to extend the database with other custom objects for other purposes, such as auditing or configuration (which would sit nicely in their own schemas). Right, that said, here’s a basic script that’ll set that up for us.
create database metastore; create login metastore with password = 'some-uncrackable-adamantium-password', default_database = metastore; use Hive; create user metastore for login metastore; go; create schema meta authorization metastore; go; grant connect to metastore; grant create table to metastore; grant create view to metastore; alter user metastore with default_schema = meta;
For simplicity I’ve named my database ‘Hive’. You can use whatever name you prefer, as we are able to specify the database name in the connection configuration.
Next of course we need to run the above hive schema creation script that we acquired from the Hive code base, in order to create the necessary database objects in the Hive metastore.
Ensure that you are logged in as the above metastore user so that the default schema above is applied when the objects are created. Execute the hive schema creation script.
The resultant schema isn’t too crazy.
You can see some relatively obvious tables created for Spark’s metadata needs. The DBS table for example lists all our databases created, and TBLS contains, yep, you guessed it, the tables and a foreign key to their related parent database record in DBS.
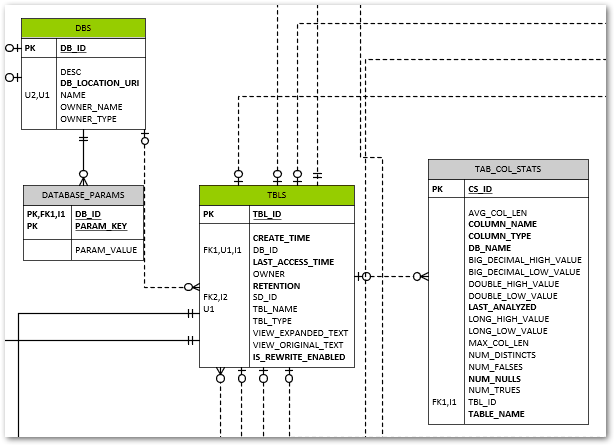
The VERSION table contains a single row that tracks the Hive metastore version (not the Hive version).
Having this visibility into the metadata used by Spark is a big benefit should you be looking to drive your various Spark-related data engineering tasks from this metadata.
Connecting to the SQL Server Hive Metastore
JDBC Driver Jar for SQL Server
One file we don’t have included as standard in the Spark code base is the JDBC driver to allow us to connect to SQL Server. We can download this from the link below.
From the downloaded archive, we need a Java Runtime Engine 8 (jre8) compatible file, and I’ve chosen mssql-jdbc-9.2.1.jre8.jar as a pretty safe bet for our purposes.
Once we have this, we need to simply copy this to the \jars directory within our Spark Home directory and we’ll have the driver available to Spark.
Configuring Spark for the Hive Metastore
Great, we have our metastore database created and the necessary driver file available to Spark for connecting to the respective SQL Server RDBMS platform. Now all we need to do is tell Spark where to find it and how to connect. There are a number of approaches to providing this, which I’ll briefly outline.
hive-site.xml
This file allows the setting of various Hive configuration parameters in xml format, including those for the metastore, which are then picked up from a standard location by Spark. This is a good vehicle for keeping local development-specific configurations out of a common code base. We’ll use this for storing the connection information such as username, password, and we’ll bundle in the jdbc driver and jdbc connection URL. A template file for hive-site.xml is provided as part of the hive binary build, which you can download at https://dlcdn.apache.org/hive/. I’ve chosen apache-hive-2.3.9-bin.tar.gz.
You’ll find a hive-site.xml.template file in the \conf subdirectory which contains details of all the configurations that can be included. It may make your head spin looking through them, and we’ll only use a very small subset of these for our configuration.
Here’s what our hive-site.xml file will end up looking like. You’ll need to fill in the specifics for your configuration parameters of course.
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>some-path\scratchdir</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>some-path\spark-warehouse</value>
<description>Spark Warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://some-server:1433;databaseName=metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>metastore</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>some-uncrackable-adamantium-password</value>
<description>password to use against metastore database</description>
</property>
</configuration>
You’ll need to copy this file to your SPARK_HOME\conf directory for this to be picked up by Hive.
Note the use of the hive.metastore.warehouse.dir setting to define the default location for our hive metastore data storage. If we create a Spark database without specifying an explicit location our data for that database will default to this parent directory.
spark-defaults.conf
This allows for setting of various spark configuration values, each of which starts with ‘spark.’. We can set within here any of the values that we’d ordinarily pass as part of the Spark Session configuration. The format is simple name value pairs on a single line, separated by white space. We won’t be making use of this file in our approach however, instead preferring to set the properties via the Spark Session builder approach which we’ll see later. Should we want to use this file, note that any Hive-related configurations would need to be prefixed with ‘spark.sql.’.
Spark Session Configuration
The third option worth a mention is the use of the configuration of the SparkSession object within our code. This is nice and transparent for our code base, but does not always behave as we’d expect. There are a number of caveats worth noting with this approach, some of which have been garnered through painful trial and error.
SparkConf.set is for Spark settings only
Seems pretty obvious when you think about it really. You can only set properties which are prefixed spark.
‘spark.sql.’ Prefix for Hive-related Configurations
As previously mentioned, just to make things clear, if we want to add any Hive settings, we need to prefix these ‘spark.sql.’
Apply Configurations to the SparkContext and SparkSession
All our SparkConf values must be set and applied to the SparkContext object with which we create our SparkSession. The same SparkConf must be used for the Builder of the SparkSession. This is shown in the code further down when we come to how we configure things on the SparkSession.
Add Thrift Server URL for Own SparkSession
The hive thrift server URL must be specified when we’re creating our own SparkSession object. This is an important point for when we want to configure our own SparkSession such as for adding the Delta OSS extensions. If you are using a provided SparkSession, such as when running PySpark from the command line, this will have been done for you and you’ll probably be blissfully unaware of the necessity of this config value. Without it however you simply won’t get a hive metastore connection and your SparkSession will not persist any metadata between sessions.
We’ll need to add the delta extensions for the SparkSession and catalog elements in order to get Delta OSS functionality.
Building on the SparkSessionUtil class that we had back in Local Development using Databricks Clusters, adding the required configurations for our hive metastore, our local SparkSession creation looks something like
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from delta import *
from pathlib import Path
DATABRICKS_SERVICE_PORT = "8787"
class SparkSessionUtil:
"""
Helper class for configuring Spark session based on the spark environment being used.
Determines whether are using local spark, databricks-connect or directly executing on a cluster and sets up config
settings for local spark as required.
"""
@staticmethod
def get_configured_spark_session(cluster_id=None):
"""
Determines the execution environment and returns a spark session configured for either local or cluster usage
accordingly
:param cluster_id: a cluster_id to connect to if using databricks-connect
:return: a configured spark session. We use the spark.sql.cerespower.session.environment custom property to store
the environment for which the session is created, being either 'databricks', 'db_connect' or 'local'
"""
# Note: We must enable Hive support on our original Spark Session for it to work with any we recreate locally
# from the same context configuration.
# if SparkSession._instantiatedSession:
# return SparkSession._instantiatedSession
if SparkSession.getActiveSession():
return SparkSession.getActiveSession()
spark = SparkSession.builder.config("spark.sql.cerespower.session.environment", "databricks").getOrCreate()
if SparkSessionUtil.is_cluster_direct_exec(spark):
# simply return the existing spark session
return spark
conf = SparkConf()
# copy all the configuration values from the current Spark Context
for (k, v) in spark.sparkContext.getConf().getAll():
conf.set(k, v)
if SparkSessionUtil.is_databricks_connect():
# set the cluster for execution as required
# Note: we are unable to check whether the cluster_id has changed as this setting is unset at this point
if cluster_id:
conf.set("spark.databricks.service.clusterId", cluster_id)
conf.set("spark.databricks.service.port", DATABRICKS_SERVICE_PORT)
# stop the spark session context in order to create a new one with the required cluster_id, else we
# will still use the current cluster_id for execution
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
return sess.builder.config("spark.sql.cerespower.session.environment", "db_connect",
conf=conf).getOrCreate()
else:
# Set up for local spark installation
# Note: metastore connection and configuration details are taken from <SPARK_HOME>\conf\hive-site.xml
conf.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
conf.set("spark.broadcast.compress", "false")
conf.set("spark.shuffle.compress", "false")
conf.set("spark.shuffle.spill.compress", "false")
conf.set("spark.master", "local[*]")
conf.set("spark.driver.host", "localhost")
conf.set("spark.sql.debug.maxToStringFields", 1000)
conf.set("spark.sql.hive.metastore.version", "2.3.7")
conf.set("spark.sql.hive.metastore.schema.verification", "false")
conf.set("spark.sql.hive.metastore.jars", "builtin")
conf.set("spark.sql.hive.metastore.uris", "thrift://localhost:9083")
conf.set("spark.sql.catalogImplementation", "hive")
conf.set("spark.sql.cerespower.session.environment", "local")
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
builder = sess.builder.config(conf=conf)
return configure_spark_with_delta_pip(builder).getOrCreate()
@staticmethod
def is_databricks_connect():
"""
Determines whether the spark session is using databricks-connect, based on the existence of a 'databricks'
directory within the SPARK_HOME directory
:param spark: the spark session
:return: True if using databricks-connect to connect to a cluster, else False
"""
return Path(os.environ.get('SPARK_HOME'), 'databricks').exists()
@staticmethod
def is_cluster_direct_exec(spark):
"""
Determines whether executing directly on cluster, based on the existence of the clusterName configuration
setting
:param spark: the spark session
:return: True if executing directly on a cluster, else False
"""
# Note: using spark.conf.get(...) will cause the cluster to start, whereas spark.sparkContext.getConf().get does
# not. As we may want to change the clusterid when using databricks-connect we don't want to start the wrong
# cluster prematurely.
return spark.sparkContext.getConf().get("spark.databricks.clusterUsageTags.clusterName", None) is not None
Note this has been updated to use the Delta OSS 1.0 library, with the handy configure_spark_with_delta_pip function.
We can test our local hive metastore is working simply by creating some objects to store therein and confirming that these are persisted across SparkSession lifetimes.
import ntpath
import posixpath
from os import path
from SparkSessionUtil import SparkSessionUtil
data_root = 'd:\dev\data'
db_name = 'test_metastore_persist'
table_name = 'test_table'
db_path = f"'{path.join(data_root, db_name)}'".replace(ntpath.sep, posixpath.sep)
spark = SparkSessionUtil.get_configured_spark_session()
spark.sql(f"""create database if not exists {db_name} location {db_path}""")
spark.sql(f"""create table if not exists {db_name}.{table_name}(Id int not null)""")
# reset our spark session
spark = None
spark = SparkSessionUtil.get_configured_spark_session()
# confirm the database and table created above are available in the metastore
spark.sql(f"show tables in {db_name}").show(truncate=False)
After recreating the spark session, we see that we still have our database and table previously created. Success!
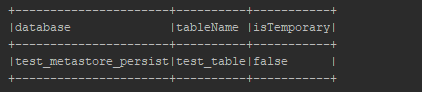
The Story So Far…
Along time ago in a gala…. no wait, stop, back up, more, more, right, thanks, that’s already been done. Right, where were we? Ah yes, so a quick summary of where we’re at with our local Spark setup and what we’ve covered off to date within this series:
- IDE integration – we’re really cooking with our code completion, support for testing frameworks, debugging, refactoring, blah de blah blah – the list goes on but you get the point. Using an IDE is hands down the way to go for the best development productivity. And productive developers are happier developers, well generally speaking anyway.
- Delta OSS functionality – bridging the gap between the data lake and data warehouse worlds. Sounds good to me.
- Our very own local hive metastore – ah bless, isn’t it cute? Even when it burps up a bit of metadata on your shoulder. Work in isolation, leverage the metadata within your code, put on your favourite Harry Belafonte album and smile.
- Work locally, unit test locally, don’t get things thrown at you for breaking shared environments. Sneer at those who don’t have the firepower of this fully armed and operational battle sta… oh no sorry, it happened again, I know, I know, I’m working on it. Okay maybe no sneering but at least feel free to be a bit smug about your databricks development endeavours.
Right so with all that said, in our next post we’ll get round to looking at some approaches to testing our code for successful Databricks deliveries.

Local Development using Databricks Clusters
In this post we’ll be looking at using our local development environment, with the various productivity benefits from IDE tools, with a Databricks cluster. We’ve covered how to use a local Spark setup, with various benefits such as cost savings and isolated working, but this will only take you so far. You might be in need of collaborative development/testing or are at the point where you simply need the power of a databricks cluster. Whatever the motivation, being able to hook your development workstation in to the databricks service is something you’ll want to consider at some point.
Wiring up with Databricks Connect
As the name suggests, this allows local connection to a databricks cluster, allowing you to issue actions against your databricks environment. To connect your favourite local development tools to your databricks cluster, you’ll need to use the ‘databricks-connect‘ python package. Before we get too giddy at this prospect there are however a number of caveats to be aware of.
Available Versions of Databricks Connect
A prerequisite of working with databricks connect against your cluster is that the cluster runtime major, minor versions match the databricks connect package major, minor version. Not all versions of the runtime are supported, which is something of a pain and does leave the tail wagging the dog in this regard. In essence, the availability of the databricks connect packages will dictate the runtime version of databricks that you choose for your development cluster. You are of course free to use a later version beyond the development environment as you won’t need databricks connect outside of this, but that does add a small element of risk regarding the disparity of runtime versions between environments.
At the time of writing, if you are going to use databricks connect, you essentially have databricks runtimes 7.3 and 8.1 to choose from (unless you stretch back to versions well out of support). If you’d like to further information on the versioning aspects, please take a look at https://docs.databricks.com/release-notes/dbconnect/index.html.
Scala and Runtime 8.1
As you’re probably going to opt for runtime 8.1, be aware that Scala developers will need to install Scala version 2.12 for local development against the cluster.
Okay now we’ve got all the caveats around versioning out of the way, we can crack on.
Setup of Databricks Connect for Azure Databricks
You can find the guide for setting up your client machines and Azure databricks workspace clusters for databricks connect at https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect. If you’ve been running Spark locally, you will need to change your PYSPARK_PYTHON and SPARK_HOME environment variables whilst using databricks connect, as mentioned in the article.
Specifying Environment Variables in PyCharm
If you are using PyCharm, you can set environment variables for each of your configurations. Go to Run | Edit Configurations… and then for the relevant configuration, amend your PYSPARK_PYTHON and SPARK_HOME variables as required as shown below.

You can easily copy the environment variables from one configuration to another using the UI.
Note: The use of other existing environment variables in the value, such as with %MY_ENV_VAR% syntax usual for embedding variables within other variable values appears to not work in PyCharm. I haven’t pursued this one and tend to take the longer way round of copying the full variable value where otherwise I would have embedded it. For our variables above this is not an issue, but something to note if you were for example using %SPARK_HOME% in you Path variable value.
Time to Check the Small Print
Before you start your local development setup with databricks connect, ensure you read the Limitations section. Two important development areas that are not supported are worth highlighting here.
- Spark Structured Streaming is not possible
- Some elements of Delta Lake APIs won’t work
The docs state that all Delta API calls are not supported, but I’ve found that some do work, such as DeltaTable.isDeltaTable, whereas DeltaTable.forPath and DeltaTable.forName do not. Also, using spark.sql(“””Create table….. using delta…”””) won’t work (contrary to the docs), complaining of not being able to instantiate a DeltaDataSource Provider. You can however still read and write data to delta tables using spark.read and spark.write.format(“delta”).save(“path/to/delta_table”).
Having this disparity between APIs available may result in you deciding to take a different approach to development that doesn’t include databricks connect when using delta lake. I tend to work locally on these aspects of the development, to the point where I’m happy to push up as jars or wheels for executing directly on the cluster.
Okay, if you’re fine with those limitations then there is one additional piece of info required for us to get started with local development using a databricks cluster.
Missing Spark Configuration Setting
The above setup guide does neglect to include a a Spark configuration value for your cluster relating to the databricks service port . With this added, the required list of cluster configuration settings is as below:
spark.databricks.service.port 8787 spark.databricks.service.server.enabled true
Add this to your Cluster via the ‘Advanced Options | Spark | Spark Config’ section and your cluster is all databricks connect friendly and ready to receive.
Create a Separate Python Environment
It makes a lot of sense to create a separate Python environment for your databricks connect package, and you’ll probably want to keep this separate from any ‘native’ PySpark installation you may already have, such as if working locally as per the previous post Local Databricks Development on Windows.
Connecting to Different Clusters
The databricks connect package uses a file in your home directory called ‘.databricks-connect‘ in order to connect to your cluster. If you are using multiple clusters for different aspects of your work you could swap various files in and out in order to manage your cluster connections. This would be pretty messy and error prone and hard to coordinate. A much better approach is to simply change the spark.configuration settings that are used for the cluster connections. Credit for this idea goes to to Ivan G in his post at https://dev.to/aloneguid/tips-and-tricks-for-using-python-with-databricks-connect-593k. We’ll cover this in the next section.
Determining the Execution Environment
We basically have three scenarios to consider when executing our Spark code for databricks.
- Local development executing against a local Spark Installation (as previously mentioned covered in the post Local Databricks Development on Windows)
- Local development executing against a databricks cluster via databricks connect
- Execution directly on a databricks cluster, such as with a notebook or job.
Our spark session will be setup differently for each of these scenarios, and it makes sense to have a way of determining programmatically which of these is relevant. There are a number of configuration settings and environment elements that we can examine to deduce this, as outlined below:
- Only scenario 3, Execution directly on a databricks cluster, will return a name from the spark configuration setting ‘spark.databricks.clusterUsageTags.clusterName‘.
- Databricks connect uses a different code base for the pyspark package, which includes an additional ‘databricks‘ directory.
I should add that these are current determinants, and that you should ensure that you test that these still hold with each change in databricks runtimes and the related databricks-connect package release.
With those conditions to work with, I have created a ‘SparkSessionUtil‘ class that configures our required Spark Session for us.
Local Spark Setup
For local Spark installations we can turn off a number of settings that don’t apply if we are not on a cluster (there are probably more but these should be a good set to run with).
Databricks Connect against a Specific Workspace Cluster
We can pass a cluster id for when working with databricks connect and wanting to use a cluster different to that set in our ‘databricks-connect‘ configuration file.
Direct Cluster Execution
If we are executing directly on our cluster (scenario 3 above) we don’t need to do anything with our Spark Session so simply return the original session.
Right, finally, some code.
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
class SparkSessionUtil:
"""
Helper class for configuring Spark session based on the spark environment being used.
Determines whether are using local spark, databricks-connect or directly executing on a cluster and sets up config
settings for local spark as required.
"""
DATABRICKS_SERVICE_PORT = "8787"
@staticmethod
def get_configured_spark_session(cluster_id=None):
"""
Determines the execution environment and returns a spark session configured for either local or cluster usage
accordingly
:param cluster_id: a cluster_id to connect to if using databricks-connect
:return: a configured spark session
"""
spark = SparkSession.builder.getOrCreate()
if SparkSessionUtil.is_cluster_direct_exec(spark):
# simply return the existing spark session
return spark
conf = SparkConf()
# copy all the configuration values from the current Spark Context
for (k, v) in spark.sparkContext.getConf().getAll():
conf.set(k, v)
if SparkSessionUtil.is_databricks_connect(spark):
# set the cluster for execution as required
# note: we are unable to check whether the cluster_id has changed as this setting is unset at this point
if cluster_id:
conf.set("spark.databricks.service.clusterId", cluster_id)
conf.set("spark.databricks.service.port", DATABRICKS_SERVICE_PORT)
# stop the spark session context in order to create a new one with the required cluster_id, else we
# will still use the current cluster_id for execution
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
return sess.builder.config(conf=conf).getOrCreate()
else:
# set up for local spark installation
conf.set("spark.broadcast.compress", "false")
conf.set("spark.shuffle.compress", "false")
conf.set("spark.shuffle.spill.compress", "false")
conf.set("spark.master", "local[*]")
return SparkSession.builder.config(conf=conf).getOrCreate()
@staticmethod
def is_databricks_connect(spark):
"""
Determines whether the spark session is using databricks-connect, based on the existence of a 'databricks'
directory within the SPARK_HOME directory
:param spark: the spark session
:return: True if using databricks-connect to connect to a cluster, else False
"""
return os.path.isdir(os.path.join(os.environ.get('SPARK_HOME'), 'databricks'))
@staticmethod
def is_cluster_direct_exec(spark):
"""
Determines whether executing directly on cluster, based on the existence of the clusterName configuration
setting
:param conf: the spark session configuration
:return: True if executing directly on a cluster, else False
"""
# Note: using spark.conf.get(...) will cause the cluster to start, whereas spark.sparkContext.getConf().get does
# not. As we may want to change the clusterid when using databricks-connect we don't want to start the wrong
# cluster prematurely.
return spark.sparkContext.getConf().get("spark.databricks.clusterUsageTags.clusterName", None) != None
# specify a cluster_id if needing to change from the databricks connect configured cluster
spark = SparkSessionUtil.get_configured_spark_session(cluster_id="nnnn-mmmmmm-qqqqxx")
And We’re ‘Go’ for Local Development using Databricks Clusters
Okay, assuming you’ve followed the setup guide at https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect, and added the omission around configuration, you should now be good to go. Go forth and develop locally whilst running your code either against your local Spark installation or your amped up, supercharged, megalomaniacal databricks clusters. Can I get a ‘Woop Woop’? No? Oh well, worth a try…
Using Your Own Libraries
One common issue when using libraries in your development that are still somewhat ‘volatile’ is that updating these on the cluster will cause issues for other users. You may be working on elements of the development that use a library version that is different to that used by a colleague, such as when referencing inhouse libraries that are still evolving.
Databricks uses three scopes for library installation, as summarised below:
Workspace Libraries
These are available across the databricks workspace, and can be referenced when installing onto clusters as required. Please see https://docs.microsoft.com/en-us/azure/databricks/libraries/workspace-libraries for more information.
Cluster Libraries
These have been installed on a cluster and can be referenced from any code running on the cluster. Please see https://docs.microsoft.com/en-us/azure/databricks/libraries/cluster-libraries for more information. The big gotcha with these is the need to restart the cluster if you need to change the library code. This is a disruption most dev teams could do without and you won’t be popular if your libraries are in a state of rapid flux.
Notebook Libraries
These are available within a single notebook, allowing the best isolation from other users’ code and the least disruption. You can read more about them at https://docs.microsoft.com/en-us/azure/databricks/libraries/notebooks-python-libraries. One pain with using %pip for dbfs-located packages results from databricks changing periods, hyphens and spaces with underscores. You will need to first rename the file back to the correct name to conform to the wheel package naming standards, in order to use %pip from the notebook.
Adding References to Your Own Versions of Libraries
If you’re not doing notebook-based development, for whatever reason, then the option of upsetting your colleagues by using cluster libraries may not sit well. You can however add the required packages for local development using databricks by adding a reference to the egg/jar to the SparkContext, using either ‘addPyFile‘ (Python) or ‘addJar‘ (Scala). This is mentioned in the databricks connect setup article at https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect. First add your files to a file share somewhere accessible to your workspace clusters, such as a storage mount point, or the dbfs:/FileStore.
The only scenario we really need to consider volatile libraries issues is when you are using databricks connect to execute against a cluster (scenario 2 above). The local Spark installation approach (scenario 1 above) is by its nature not shared, so we’re free to use whatever there. We can usually assume that if you are executing directly on a cluster (scenario 3 above) that you have installed the required libraries on the cluster and as such the packages will be available.
Here’s some code for using our own library versions.
Python
if SparkSessionUtil.is_databricks_connect(spark):
spark.sparkContext.addPyFile("dbfs:/FileStore/jars/lib1-0.3-py3.8.egg")
# insert additional libraries here...
from lib1 import mod1._
some_blah = mod1.some_method('blah')
if SparkSessionUtil.IsDatabricksConnect(spark){
spark.sparkContext.addJar("dbfs:/FileStore/jars/lib1_2.12-0.3.jar")
// insert additional libraries here...
}
import lib1.mod1
val someBlah = mod1.someMethod("blah")
Notice that we have moved any import statements to after the adding of the referenced library files.
If you do find that you need to extend this to scenario 3, you can simply add a condition based on the ‘SparksessionUtil.is_cluster_direct_exec‘ method. At some point however you’ll probably want to use cluster-installed libraries.
If you add the above to your code entry point, including your referenced libraries as necessary, you can then manage your libraries’ versions independently of the cluster. This avoids disruption to other team members and any incoming low-flying donuts/staplers/deckchairs that may result.
Using DBUtils
Limitations with Databricks Connect
You’ll only be able to use the secrets and file system (fs) elements of DBUtils if you are using databricks connect. This shouldn’t be an issue as the other elements are generally more for notebook development.
Compiling with Scala 2.12
If you are developing with Scala against Spark 3.0+, such as with databricks runtimes 8.x, you won’t have the required DBUtils library available. You can find the DBUtils version for Scala 2.11 on Maven, but 2.12 is not there. It is however available on the driver node of your clusters. You can use the Web Terminal within the Databricks service to connect to the driver node and download from there, for local development using databricks. First you’ll need to copy it from the driver node’s source directory to somewhere more accessible. The command below will do this for those not familiar with bash.
# Create a directory within the FileStore directory, which is available from our workspace mkdir dbfs/FileStore/dbutils # copy from the driver node jars directory to our new accessible dbutils directory cp /databricks/jars/spark--dbutils--dbutils-api-spark_3.1_2.12_deploy.jar dbfs/FileStore/dbutils/
You can then either use the databricks CLI to copy across locally, or simply browse to the file in your web browser. If you do the latter you’ll need to grab your workspace URL from the Azure Portal – you’ll find it top right of the workspace resource.

Your URL will have a format like that below.
https://adb-myorgidxxxxx.nn.azuredatabricks.net/?o=myorgidxxxxx
You can access the file required by adding the file path, where ‘/files/’ refers to the ‘FileStore’ source, so ‘/files/dbutils/spark–dbutils–dbutils-api-spark_3.1_2.12_deploy.jar’ is our file of interest.
https://adb-myorgidxxxxx.nn.azuredatabricks.net/files/dbutils/spark–dbutils–dbutils-api-spark_3.1_2.12_deploy.jar?o=myorgidxxxxx
You can then use this jar file for local development with Scala 2.12. Notice the naming convention used includes the Scala version. Now can I get that ‘Woop Woop’? I can, oh that’s wonderful. I’m welling up here…
Thanks for Reading
You should hopefully have a good few things to help you with your databricks development by this point in our series. We’ve covered setting up your own local Spark and also local development using databricks clusters, thereby catering for the most productive development scenarios. You’ll be cranking out great code in no time via your favourite development tools, with integrated support for testing frameworks, debugging and all those things that make coding a breeze. Ta ta for now.

Local Databricks Development on Windows
This post sets out steps required to get your local development environment setup on Windows for databricks. It includes setup for both Python and Scala development requirements. The intention is to allow you to carry out development at least up to the point of unit testing your code. Local databricks development offers a number of obvious advantages. With Windows being a popular O/S for organisations’ development desktops it makes sense to consider this setup. Considerations for cost reduction, developing offline, and, at least for minimal datasets, faster development workflow as network round-tripping is removed, all help. Right, with that said, let’s take a look at what we need to get started. I’ll split things into core requirements, just Python, just Scala, and Python and Scala, to cover off the main development scenarios. Apologies in advance to R users as not being an R user I won’t be covering this.
Core Requirements
Install WinUtils
This is a component of the Hadoop code base that is used for certain Windows file system operations and is needed for Spark to run on Windows. You can read about how to compile your own version from the Hadoop code base, or acquire a precompiled version, in my post on the subject here. I’ll skip to the point where you have the compiled code, either from downloading from GitHub precompiled, or by compiling from source.
Which version of WinUtils?
Spark can be built against various versions of Hadoop, and adopts a naming convention in its tar or zip archive that includes both the Spark version and Hadoop version, ‘Spark-<spark-version>-<bin/src>-hadoop<hadoop-version>.tgz‘, e.g. Spark-3.1.2-bin-hadoop3.2.tgz. If you are planning on using the PySpark python package for development you will need to use the version of Hadoop that is included.
On non-windows environments you can choose which version of Hadoop to include with your PySpark by setting the PYSPARK_HADOOP_VERSION environment variable prior to calling ‘pip install pyspark=<version>’, however this doesn’t appear to work for Windows, forcing you to use the default version of Hadoop for the package. For PySpark 3.1.2, this is Hadoop 3.2. For those interested, further information on hadoop version-specific installs of PySpark on non-windows systems is available at https://spark.apache.org/docs/latest/api/python/getting_started/install.html.
As we’re on Windows, we’ll go with our PySpark 3.1.2. and Hadoop 3.2, which means we need WinUtils from the Hadoop 3.2 build.
Precompiled Code
Simply copy this to a local folder, e.g. D:\Hadoop\WinUtils, and make a note of the ‘\bin‘ subdirectory which contains the winutils.exe file.
Own Compiled Code
If you’ve built your own winutils.exe, you’ll need to create a \bin directory to house, e.g. D:\Hadoop\WinUtils\bin and copy winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files here.
Environment Variables
HADOOP_HOME
You then need to add an environment variable ‘HADOOP_HOME‘ for Spark to understand where to find the required Hadoop files. You can do this using the following powershell:
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'D:\Hadoop\winutils', [System.EnvironmentVariableTarget]::Machine)
Note: This needs to be the name of the parent of the bin directory, with no trailing backslash.
As environment variables are initialised on startup of terminals, IDEs etc, any that are already open will need to be reopened in order to pick up our ‘HADOOP_HOME‘.
Path
We’ll also need to add the path to the bin directory to our Path variable, if we want to invoke ‘winutils’ from the command line without using the full path to the .exe file. The following is based on a path of D:\Hadoop\winutils\bin for our winutils.exe.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Hadoop\winutils\bin;", [System.EnvironmentVariableTarget]::Machine)
Java JDK
Spark requires Java 1.8 to run. It won’t run with later versions, so we need to be specific here. You can download either the Oracle SE JDK here, or the OpenJDK here. Please note the change in the licencing agreement if opting for Oracle SE and using in commercial development.
Run the installer, following the desired options and make a note of your installation path.
Environment Variables
JAVA_HOME
This should have been set by the installer and will point to the root of your JDK installation.
Path (Optional)
This will make the various executables within the JDK accessible without requiring an explicit path, something of use for any future Java development. It is not required for our Spark installation purposes but I’ve included this for completeness here should you want to use these.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Java\jdk1.8.0_191\bin;", [System.EnvironmentVariableTarget]::Machine)
Okay, that’s us done with the core requirements parts. Now onto the development scenario specifics.
Python-Only Development
Install Anaconda
This is my preferred option for getting Python setup for data development. Local databricks development can involve using all manner of python libraries alongside Spark. Anaconda makes managing Python environments straight forward and comes with a wide selection of packages in common use for data projects already included, saving you having to install these. You can run Spark without this if you prefer, you’ll just have to download Python (recommended 3.7 but min. 3.5 for Windows) and configure environments using the Python native tools for this, none of which is particularly difficult. I won’t cover that approach here as this is easily done with the help of a quick Google search.
You can download Anaconda for Windows here.
New Python Environment (Optional)
It may make sense to create a separate environment for your Spark development. You can if you prefer simply use the ‘base’ environment, else you can create your own via either the Anaconda prompt or the Anaconda Navigator. Both are well documented and so again I won’t be detailing here. I’ve created a ‘pyspark’ environment for this purpose. If you do create a new environment make sure that you activate this for any Python steps that follow. This is something often missed if you are not familiar with working with Python environments.
Install PySpark
Using either the Anaconda prompt or Anaconda Navigator install the pyspark package. Due to a compatibility issue with the latest delta.io code and Spark 3.1, if you are intending on using databricks Delta (see below), the latest version you can specify is version 3.0.0 rather than the current 3.1.1 version. This issue exists only with the OSS version of the Delta code base and not with the databricks commercial offering.
Note: The pyspark package includes all required binaries and scripts for running Spark (except the WinUtils files noted above required for Windows). It is not required to download Spark separately for local databricks development if using pyspark.
Scala-Only Development
If you have no Python installation and want to develop using only Scala, then you will need to take a slightly different approach to running Spark.
Note: Before considering Scala only, if you are planning on using Databricks Connect be aware that you will need to have Python installed, so your better option will probably be as outlined in the ‘Python and Scala Development’ section below.
Install Spark
Without pyspark installed, for local databricks development you’ll need to download the required Spark binaries, which can be done here. You can choose either the download with or that without Hadoop for our purposes, either is fine. The main difference between these is the inclusion of about 70MB of additional jars in the \jars directory for the Hadoop download. Extract these to a directory of your choosing such as D:\Spark. We’ll need to add some environment variables as below, so for now make a note of the directory chosen and we’re done for now.
Scala Development Environment
We won’t cover how to setup the Scala environment itself. You can find details here for the Intellij IDE, or here for VSCode, which uses the ‘Metals’ language server. You can also simply install the Scala binaries, the latest version of which are available here, and then use the command line. You can find instructions here if required.
Python and Scala Development
If you are developing in both Python and Scala, not uncommon if you have both ‘Data Engineer’ and ‘Data Scientist’ aspects to your work, you will not need all the steps outlined above for ‘Scala-Only Development’. Follow the Python-Only steps, which will install Spark via the pyspark Python package, and then simply setup your development environment as mentioned in the ‘Scala-Only Development – Scala Development Environment’ section above.
Spark Environment Variables
Depending on whether you have used the pyspark Python package to provide the Spark binaries for your local databricks development, or whether you have downloaded Spark separately, you will need to amend the following based on the destination of your files.
SPARK_HOME
This should be set to the root of the Spark files. For pyspark, you will find the package installed to either <PathToAnaconda>\Lib\site-packages\pyspark, e.g. D:\Anaconda3\Lib\site-packages\pyspark, if you are using the ‘base’ environment, or if you have created your own environment you’ll find the default path at <PathToAnaconda>\Envs\<EnvName>\Lib\site-packages\pyspark. Amend the following powershell accordingly.
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('SPARK_HOME', 'D:\Anaconda3\envs\pyspark\Lib\site-packages\pyspark', [System.EnvironmentVariableTarget]::Machine)
Path
The following will need to be added to your path in order to run the various Spark commands from the command line:
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
Here’s some powershell I made earlier…
# Append required pyspark paths to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};${env:SPARK_HOME}\bin;${env:SPARK_HOME}\sbin;", [System.EnvironmentVariableTarget]::Machine)
Add Databricks Delta Libraries
The databricks Delta libraries for Spark add some fantastic functionality to Spark SQL and are very much revolutionising data lakes and data warehousing with their ‘LakeHouse‘ architecture. You can read all about Delta here. Suffice to say that these libraries will probably feature in your local databricks development.
Note that there are actually two different development streams for Delta. One is that used on the commercial databricks service, The other is that made Open Source at the previous link, which we’ll be using. I’ll refer to this as Delta OSS to avoid confusion.
Known Issue with Delta OSS 0.8.0 and Spark 3.1
Unfortunately there is an issue with using Delta OSS 0.8.0 with Spark 3.1. The setting of the Spark configuration ‘spark.sql.catalog.spark_catalog‘ to ‘org.apache.spark.sql.delta.catalog.DeltaCatalog‘ will result in an error that prevents using Delta. Some users have suggested simply omitting setting this configuration value, however this then causes further headaches when working with delta tables. You’ll get errors relating to the table metadata, such as ‘Cannot write nullable values to non-null column <colName>‘, and errors trying to cast values to dates and all sorts of other woes. These errors only really hint at what might be up, which appears to be the lack of the DeltaCatalog required for correct table metadata storage. The only real solution is to use Spark 3.0 with Delta OSS, which for local development should not be an issue. I’m told this issue should be resolved in Spark 3.2. As previously mentioned, there is no issue with the commercial offering available on the databricks platform, only with the Delta OSS code.
You can read the quickstart guide at delta.io here to see how we can use the Delta libraries for the various ways of working locally you may have adopted. I’ll include the Python and Scala ones here for completeness.
Delta-Spark 1.0.0 PyPI Package
With the version 1.0.0 release of Delta OSS we now have a PyPI package available. This is great news. We can now use pip to install the package as below:
pip install delta-spark=1.0.0
This will install the Python wrappers for Delta OSS but will not include the related Scala jar files that are the core of the code base. The jars will be fetched at runtime as described below:
Acquiring the Scala Library and Enabling the Delta OSS Functionality
Delta OSS 0.8.0
Python
Add the following code to your Spark session configuration
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.jars.packages", "io.delta:delta-core_2.12:0.8.0") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
from delta.tables import *
The ‘spark.jars.packages‘ link will cause the jar files to be downloaded from Maven and stored in your local Ivy package store, the default location being .ivy2\jars within your user home directory.
Including the Libraries for Development
If you open up the io.delta_delta-core_2.12-0.8.0.jar archive file (any zip program should do) you will see that there is also a Python file included, delta\tables.py.

This contains the python code for interfacing with the underlying Scala implementation. With the jar added to your Spark session you are then able to import the Python module ‘delta\tables.py‘ and add Delta table functionality to your efforts.
Code Completion/Linting in PyCharm
Pycharm won’t recognise the tables.py file that is contained in the jar, as it is only visible to Spark at runtime. The delta code base is not available as a Python package and so cannot be ‘installed’ to Python and easily recognised by PyCharm. In order to have fully functional code completion you will need to download the source code and add the required path to the project structure as a ‘Content Root’ so that it is visible. You can download the required release for your local databricks development from GitHub here. Unzip it to a suitable location locally and within PyCharm, in File | Settings | Project: <projectName> | Project Structure, add the python\delta folder as a ‘Content Root’ as shown below.

By using the above ‘from delta.tables import *‘ you will then have Delta code completion within your PyCharm environment.
Delta OSS 1.0.0
With the release of the PyPI package for delta-spark, we have none of the above hoops to jump through to get our Delta OSS code working in Python. As it is available in our virtual environment, we can simply import the required modules and code completion/Linting will be available to our IDE. Happy days. We do however still need to acquire the Scala library and enable the required functionality. The Spark Session configuration is very similar to that for Delta OSS 0.8.0 above, with the added bonus of a handy utility function ‘configure_spark_with_delta_pip’ to ensure that we grab the correct Scala jar file without hard coding the version. Pass in your configured Spark Session Builder object, and this will add the ‘spark.jars.packages‘ configuration value for the required jar that we had to add ourselves in 0.8.0.
# delta-spark 1.0.0 brings a handy configuration function for acquiring the Scala jars...
spark = configure_spark_with_delta_pip(
pyspark.sql.SparkSession.builder.appName("MyApp")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
).getOrCreate()
from delta.tables import *
Add the jar file to PySpark
If you are using the PySpark package to provide your local Spark code base, as opposed to downloading the Spark code and installing to a local directory, you’ll need to add the required delta-core jar file to your PySpark\jars folder. Simply copy this from the .ivy location above and you’re done.
Scala
Maven
Add the following to your Maven pom file:
<dependency> <groupId>io.delta</groupId> <artifactId>delta-core_2.12</artifactId> <version>0.8.0</version> </dependency>
Note: Change your version accordingly to whatever version of Delta OSS you are using.
SBT
If using SBT, you can simply add the following to your build.sbt file:
libraryDependencies += "io.delta" %% "delta-core" % "0.8.0"
Note: Change your version accordingly to whatever version of Delta OSS you are using.
You now have Delta functionality within your locally developed Spark code. Smokin’…
And We’re Good To Go…
We now have our local databricks development environment setup on Windows to allow coding against Spark and Delta. This won’t necessarily serve all your needs, with aspects like integration testing probably falling out of scope. It should however remove the need to always have clusters up, reduce disruption that would be caused on a shared development environment, as well as increasing productivity during development. Personally I find it well worth setting up and hope you will find considerable benefits from this way of working.
In the next post we’ll be looking at hooking up databricks connect with your local dev tools for when you need to run against a databricks cluster. Thanks for reading and see you soon.

Build Your Own WinUtils for Spark
The option of setting up a local spark environment on a Windows build, whether for developing spark applications, running CI/CD activities or whatever, brings many benefits for productivity and cost reduction. For this to happen however, you’ll need to have an executable file called winutils.exe. This post serves to supplement the main thread of the series on Development on Databricks, making a stop at C++ world (don’t panic!) as we handle the situation where you are required to build your own WinUtils executable for use with Spark. It is intended for an audience unfamiliar with building C++ projects, and as such seasoned C++ developers will no doubt want to skip some of the ‘hand-holding’ steps.
What Does Spark Need WinUtils For?
In order to run Apache Spark locally, it is required to use an element of the Hadoop code base known as ‘WinUtils’. This allows management of the POSIX file system permissions that the HDFS file system requires of the local file system. If Spark cannot find the required service executable, WinUtils.exe, it will throw a warning as below, but will proceed to try and run the Spark shell.

Spark requires that you have set POSIX compatible permissions for a temporary directory used by the Hive metastore, which defaults to C:\tmp\hive (the location of this can be changed as described here ). In order to set these POSIX permissions you need to use WinUtils, and without these permissions being set correctly any attempt to use Spark SQL to access the Hive metastore will fail. You’ll get an error complaining about lack of writable access to the above scratch directory and Spark will throw a full blown sulk like a kid deprived of their Nintendo Switch. Here’s a sulk it threw earlier…
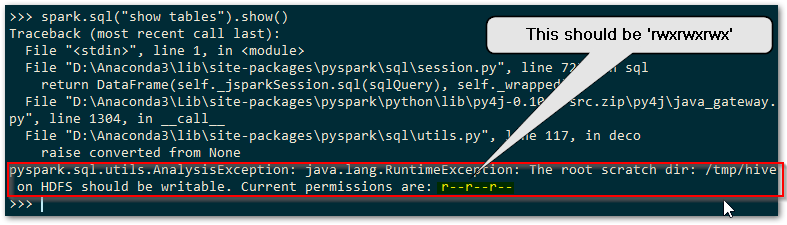
You’ll need to use WinUtils as below in order to set the POSIX permissions for HDFS that the Hive metastore will be happy with.
# set the rwxrwxrwx POSIX permissions winutils chmod -R 777 c:\tmp\hive
So if you’re on Windows and want to run Spark, WinUtils is a necessity to get going with anything involving the Hive metastore.
Why Build Your Own?
Existing Prebuilt WinUtils Repositories
There are GitHub repositories that are independently maintained, available here, with a previous one here (no longer maintained) that contains the compiled exe file and any supporting libraries, for the various versions of the Hadoop code base included within Apache Spark. If you don’t need to provide transparency of the source of the code used you can always simply grab the compiled files for local use rather than going to the trouble of compiling your own.
The maintainer of the second compiled WinUtils repo above details the process that they go to in order to ensure that the code is compiled from the legitimate source, with no routes for malware to infiltrate. This may however still not be acceptable from a security perspective. The security administrators and custodians of your systems will quite probably have tight controls on you simply copying files whose originating source code cannot be verified 100%, for obvious reasons. We all know the perils of simply downloading and running opaque executables and so the option to build your own winutils executable for Spark will be welcome.
Compiling from Source
WinUtils is included within the main Apache Spark GitHub repository, with all dependent source code available for inspection as required. As you can see from the repo, the Hadoop code base is huge, but the elements we really need are only a small fraction of this. Getting the whole Hadoop code base to build on a Windows machine is no easy task, and we won’t be trying this here. You’ll need a very specific set of dependent components and a dedicated build machine if you want to build the full Hadoop repo, which is the approach taken in the above prebuilt repos. You can find a number of tutorials on how to do this on the web, such as the one found here. Note the specific components required based on the code base. For our purposes we can focus on just the WinUtils code itself. I’ll be using the ‘branch-3.2’ branch for this exercise.
So having cloned/downloaded the Apache Hadoop repo and checked out to the ‘branch-3.2’, the desired WinUtils code can be found within our local repo at
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\winutils
and
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native
You’ll notice that the above code is written in C/C++, and so if we’re going to build the executable we need to be able to compile C/C++ code. No great surprises there. I should probably confess at this point that I haven’t touched C++ for a good few years to any advanced degree, so I’m far removed from being a C++ developer these days and am going to simplify things here (to avoid confusing me and possibly you).
Tools for the Job
If you have Visual Studio installed you can simply extend the Features to include C++ desktop applications, thereby gaining the required compiler, linker etc. If you don’t have Visual Studio, you can still get the Build Tools as a separate download, available here for VS2019. Once you have the required tools, we can look at what is required to build your own WinUtils executable.
Building the Code
Cue trumpets… pap pap pap pap paaaaeeeerrrrr…. oh hold on, there’s still a little way to go. Trumpets, come back in a bit, grab a coffee, play some Uno or something, won’t be long, nearly there.
Desired Output
In the latest version of the WinUtils code, there are two projects in the WinUtils directory. One is for the WinUtils.exe used directly from Spark on Windows, and the other is for a library, libwinutils.lib, that will be referenced from WinUtils.exe. If you look at the precompiled repos mentioned above, for each version of Hadoop you’ll see a number of files that are output in addition to the two previously mentioned. We’ll be needing the hadoop.dll and hadoop.lib files for our purposes of running Spark on Windows. We don’t need the hdfs.*, mapred.* or yarn.* files as these components of Hadoop won’t be of interest.
We want to be able to compile both the winutils, libwinutils and native projects and make use of the resultant files. If you are not familiar with building code using Microsoft Visual Studio and associated tooling, these files will be generated in a default output location such as winutils\debug or winutils\Release, depending on the configuration chosen (more on that below). Okay, with that end goal in mind, let’s look to building the code.
Retarget Projects with Visual Studio
The projects are based on the VS2010 IDE, so you’ll get upgrade messages when opening if you are on a later version.
Assuming you are on a later Windows build than Windows 8.1, you will need to change the Build tools and Windows SDK targeted by the solution projects. The first time you open the winutils.sln or native.sln files you will be greeted with the following dialogue and should choose whatever is the latest installed on your system. For me this was v142 as I’m on Visual Studio 2019, and SDK 10.0.19041.0.
WinUtils Solution Code Amendments Required
Okay, so we’ve grabbed the code base and installed the required tools to build the code. There are a couple of things that need to be considered for a successful build of your own WinUtils for Spark.
libwinutils.c Issues?
You’ll see the following errors in the libwinutils.c source file, which imply an issue with the code.

However, the issue is actually with the lack of values for the preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE.
WSCE Preprocessor Directive Values
The preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE can be seen defined within the winutils and libwinutils projects, as the project file excerpt below shows.

Notice that they are populated from parameters passed in to the build, as denoted by the WSCE_CONFIG_DIR=$(WsceConfigDir) syntax. So when building the winutils project it expects these values to be passed in. Right, time to find what values are used in the Hadoop code base to see the relevance of this…
Values from Maven Pom Files
In order to understand what parameters are required to be passed to the build, we need to take a look at the Maven pom file that is used to build this part of the code base, found at
\hadoop-trunk\hadoop-common-project\hadoop-common\pom.xml
Firstly, at the top of the file, we see the following properties defined:


The various parameters passed define the configuration, platform, output directories etc, and also the two expected values, WsceConfigDir, and WsceConfigFile that will feed the preprocessor directives mentioned. These are taken from the property references ${wsce.config.dir} and ${wsce.config.file} respectively. The values for these are supplied, as we’ve just seen, in the property definitions at the top of the pom file. Right, glad we cleared that one up.
For context, these values are used as part of the Yarn Secure Containers setup, which you can read about here. We’ll need to ensure that these values are passed in for each of our build methods detailed below. As we won’t actually be using the Yarn elements for our purposes of running local Spark, we don’t need to concern ourselves with the directory and file in question not being available. We can pass empty strings, “”, for each if we want, use the values from the pom file, or use other string values. I’m going to stick with the pom file values for this exercise.
The code within the hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native folder that creates the hadoop.dll and hadoop.lib files requires no amendment and should compile without issue.
Building the WinUtils Solution with Visual Studio
Add Preprocessor Directives
On the winutils Poject Properties dialogue, choose your required Configuration. In the Configuration Properties | C/C++ | Preprocessor | Preprocessor Definitions select ‘Edit…’ to amend the values, as shown below:
You’ll see the evaluated values in the second box. I’ve edited one below to show this taking effect. Notice that WSCE_CONFIG_FILE is still undefined as far as Visual Studio is concerned. This will also need to have a value as well as mentioned above.
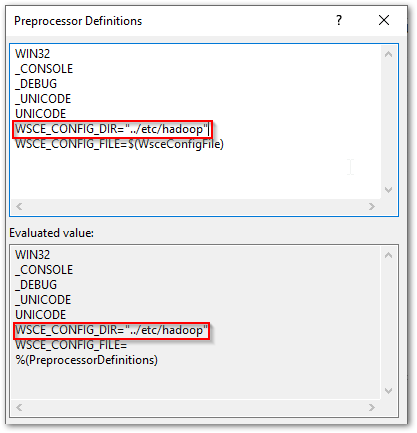
Do the same for the libwinutils project.
Issues Building on x64 Windows
By default, the original projects are configured to build against the x86 Windows platform. If you try and build using this on a x64 Windows machine, you will probably encounter the error below.

This can throw you off the scent a little as to the real issue here. You have the build tools installed as part of the Visual Studio setup for C++ projects, so why all the belly aching? Well, you’ll need to change the project configurations to build vs x64, as the build tools you have installed will be for this architecture.
If you are on x64 Windows, be sure to change the project configurations so that they build against the x64 rather than x86 platform, to avoid the issue mentioned above. This is done from Build | Configuration Manager… as shown below:
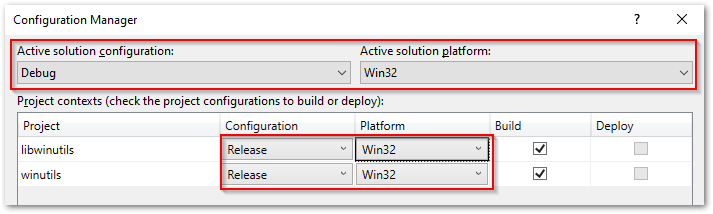
Build Your Solution
Right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B, and this will build first the libwinutils project (a dependency of winutils) and then the winutils project, to the output directories expected for your configuration.
Building the WinUtils Solution with MSBuild
Opening up a ‘Developer Command Prompt for Visual Studio’, you’ll have access to MSBuild from the command line. If you have added the path to MSBuild.exe to your ‘Path’ environment variable you will have access to this also from a regular command prompt. Navigate to your winutils solution directory.
As with the Visual Studio method, you’ll need to specify the correct platform if you are on x64, as it will default to an x86 build. Otherwise, you’ll get the same error as shown in the Visual Studio section above regarding missing build tools. It would be nice if MSBuild defaulted to use the same platform as the tooling for your installation. A simple parameter addition is all that is required to sort this.
In addition, add the parameters as defined in the Maven pom file , resulting in the MSBuild command as below:
rem output for the build will be to the winutils\bin directory MSBuild winutils.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\Winutils\ /p:WsceCOnfigDir="../etc/config" /p:WsceConfigFile="wsce-site.xml"
Execute this from the winutils solution directory to ensure the relative paths are as desired. You outputs will be built and output to the winutils\bin directory specified.
Building the Native Solution with Visual Studio
As mentioned, there are no code amendments required for the native.sln file that creates hadoop.dll and hadoop.lib. You will however need to change the configuration to x64 as necessary, as per ‘Issues Building on x64 Windows’ above. Once that is done, right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B and your code will be output to the respective debug or release folders.
Building the Native Solution with MSBuild
Follow the above ‘Building the WinUtils Solution with MSBuild’, navigating instead to the native solution directory and substituting the following MSBuild command.
rem output for the build will be to the native\bin directory MSBuild native.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\native\"
You outputs will be built and output to the native\bin directory specified.
A Build of Our Very Own WinUtils for Spark
Well technically not really ‘ours’, as those nice dedicated Hadoop developers did all the real work, but anyway. So now you have a build of your own winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files for winutils from known source code. This ticks those security checkboxes nicely. Bring the trumpeters back in…yay! Oh, they’ve gone home, never mind, improvise. Woop woop, papapapapa etc. etc. Take a bow.
Using Your WinUtils Executable
Destination Directory
In order for Spark to use the WinUtils executable, you should create a local directory with a ‘\bin’ subdirectory as suggested below:
D:\Hadoop\winutils\bin
Copy the winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files files generated earlier to this destination.
Environment Variables
HADOOP_HOME
You then need to add an environment variable ‘HADOOP_HOME’ for Spark to understand where to find the required Hadoop files. You can do this using the following powershell:
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'D:\Hadoop\winutils', [System.EnvironmentVariableTarget]::Machine)
Note: This needs to be the name of the parent of the bin directory, with no trailing backslash.
As environment variables are initialised on startup of terminals, IDEs etc, any that are already open will need to be reopened in order to pick up our ‘HADOOP_HOME’.
Path
We’ll also need to add the path to the bin directory to our Path variable, if we want to invoke ‘winutils’ from the command line without using the full path to the .exe file.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Hadoop\winutils\bin;", [System.EnvironmentVariableTarget]::Machine)
With that done we are all set to use this with our local Spark installation.
Signing Off…
Something of a diversion from the general world of data analytics this time, but for those who need to run Spark on Windows with no awkward questions about where that exe came from, this article should be of benefit. In the next post in this series we’ll look at setting up Spark locally, something that is not half as scary as it sounds. It is also at least twice as useful as you might initially think, maybe even three times. Till next time.



