Azure Data Factory Development with GitFlow – Part 1
If you’re using or planning to use Git integration with Azure Data Factory then it’s well worth taking the time to define a suitable branching model for managing the various life-cycles of your project (think feature, hotfix and release). In this short series, I’ll discuss how we can structure our Azure Data Factory development with GitFlow, an easy to comprehend branching model for managing development and release processes.
Part 2: Implementation Detail
In part 1 of this series, you’ll get an overview of the various components which make up the solution. I’ll follow this up in part 2 with the implementation detail on how to deploy and configure your Data Factory environments to tie them in with the workflow. If all goes to plan we should land up with something along the lines of the below:
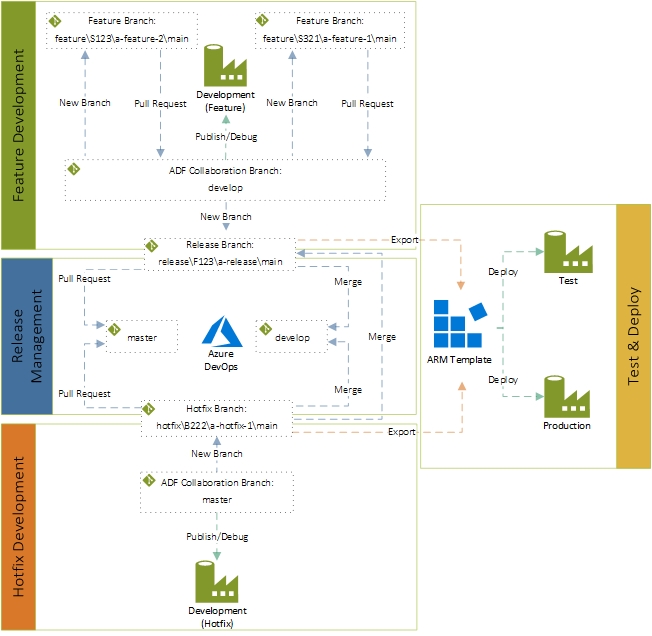
Component Overview
Now that we sort of know where we’re heading, let’s take a closer look at a few of the components that will make up the solution, namely:
- Git integration in Azure Data Factory UI for maintaining our source code
- GitFlow branching model, a structured approach to align our source code with the project life-cycle
- Continuous integration and delivery (CI/CD) in Azure Data Factory for the deployment of Data Factory entities (pipelines, datasets, linked services, triggers etc.) across multiple environments
- Azure DevOps for additional controls not available in the Azure Data Factory user interface
- Azure Data Factory for obvious reasons
Git integration in Azure Data Factory UI
With Azure Data Factory Git integration you can source control your Data Factory entities from within the Azure Data Factory UI, unfortunately, it does come with a few bugbears:
- Changes to the Data Factory automatically result in a commit e.g. new ADF entity (pipeline, connection etc.) = new commit
- Assigning Azure DevOps work items to a commit is not possible (use Azure DevOps instead)
- Merging between branches is only possible as part of a pull request
- The ability to publish a Data Factory is available from the collaboration branch only
For a more detailed look at the Git integration functionality in Azure Data Factory, have a read through the official documentation.
GitFlow branching model
First introduced by Vincent Driessen, GitFlow is a branching model for Git repositories which defines a method for managing the various project life-cycles. As with all things in life, there are lovers and haters but personally, I’m very fond of the approach. Having used it successfully on numerous projects I can vouch that, on more than one occasion, it has saved me from a merge scenario not too dissimilar to Swindon’s Magic Roundabout.
For those of you not familiar with GitFlow it’s well worth spending a few minutes reading through the details at nvie.com. In summary, and for the purpose of this post, it uses a number of branches to manage the development life-cycle namely master, develop, release, hotfix and feature. Each branch maintains clean, easy to interpret code which is representative of a phase within the project life-cycle.

Continuous integration and delivery (CI/CD) in Azure Data Factory
Continuous integration and delivery, in the context of Azure Data Factory, means shipping Data Factory pipelines from one environment to another (development -> test -> production) using Azure Resource Manager (ARM) templates.
ARM templates can be exported directly from the ADF UI alongside a configuration file containing all the Data Factory connection strings and parameters. These parameters and connection strings can be adjusted when importing the ARM template to the target environment. With Azure Pipelines in AzureDevOps, it is possible to automate this deployment process – that’s possibly a topic for a future post.
For a more detailed look at the CI/CD functionality in Azure Data Factory, have a read through the official documentation.
Azure DevOps
Azure DevOps is a SaaS development collaboration tool for doing source control, Agile project management, Kanban boards and various other development features which are far beyond the scope of this blog. For the purpose of this two-part post we’ll primarily be using Azure DevOps for managing areas where the ADF UI Git integration is lacking, for example, pull requests on non-collaboration destination branches and branch merges.
Azure Data Factory
To support the structured development of a Data Factory pipeline in accordance with a GitFlow branching model more than one Data Factory will be required:
- Feature and hotfix branch development will take place on separate data factories, each of which will be Git connected.
- Testing releases for production (both features and hotfixes) will be carried out on a third Data Factory, using ARM templates for Data Factory entity deployment without the need for Git integration.
- For production pipelines, we’ll use a fourth Data Factory. Again, as per release testing, using ARM templates for Data Factory entity deployment without the need for Git integration.
Of course, there are no hard or fast rules on the above. You can get away with using fewer deployments if you’re willing to chop and change the Git repository associated with the Data Factory. There is a charge for inactive pipelines but it’s fairly small and in my opinion not worth considering if additional deployments are going to make your life easier.
…to be continued
That covers everything we need, I hope you’ve got a good overview of the implementation and formed an opinion already on whether this is appropriate for your project. Thanks for reading. Come back soon for part 2!



