
The Hive MetaStore and Local Development
In this next post in our series focussing on Databricks development, we’ll look at how to create our own Hive metastore locally using SQL Server, and wire it up for the use of our development environment. Along the way we’ll dip into a few challenges with getting this running with your own projects and how to overcome them. This should provide us with our final element of our local Spark environment for Databricks development.
The Hive Metastore
Part of the larger Apache Hive data warehouse platform, the Hive metastore is a repository for details relating to Hive databases and their objects. It is adopted by Spark as the solution for storage of metadata regarding tables, databases and their related properties. An essential element of Spark, it is worth getting to know this better so that it can be safeguarded and leveraged for development appropriately.
Hosting the Hive Metastore
The default implementation of the Hive metastore in Apache Spark uses Apache Derby for its database persistence. This is available with no configuration required but is limited to only one Spark session at any time for the purposes of metadata storage. This obviously makes it unsuitable for use in multi-user environments, such as when shared on a development team or used in Production. For these implementations Spark platform providers opt for more robust multi-user ACID-compliant relational database product for hosting the metastore. Databricks opts for Azure SQL Database or MySQL and provides this preconfigured for your workspace as part of the PaaS offering.
Hive supports hosting the metastore on Apache Derby, Microsoft SQL Server, MySQL, Oracle and PostgreSQL.
SQL Server Implementation
For our local development purposes, we’ll walk through hosting the metastore on Microsoft SQL Server Developer edition. I won’t be covering the installation of SQL Server as part of this post as we’ve got plenty to be blabbering on about without that. Please refer to the Microsoft Documentation or the multitude of articles via Google for downloading and installing the developer edition (no licence required).
Thrift Server
Hive uses a service called HiveServer for remote clients to submit requests to Hive. Using Apache Thrift protocols to handle queries using a variety of programming languages, it is generally known as the Thrift Server. We’ll need to make sure that we can connect to this in order for our metastore to function, even though we may be connecting on the same machine.
Hive Code Base within Spark
Spark includes the required Hive jars in the \jars directory of your Spark install, so you won’t need to install Hive separately. We will however need to take a look at a few of the files provided in the Hive code base to help with configuring Spark with the metastore.
Creating the Hive Metastore Database
It is worth mentioning at this point that, unlike Spark, there is no Windows version of Hive available. We could look to running via Cygwin or Windows Subsystem for Linux (WSL) but we don’t actually need to be running Hive standalone so no need. We will be creating a metastore database on a local instance of SQL Server and pointing Spark to this as our metadata repository. Spark will use its Hive jars and the configurations we provide and everything will play nicely together.
The Hive Metastore SchemaTool
Within the Hive code base there is a tool to assist with creating and updating of the Hive metastore, known as the ‘SchemaTool‘. This command line utility basically executes the required database scripts for a specified target database platform. The result is a metastore database with all the objects needed by Hive to track the necessary metadata. For our purposes of creating the metastore database we can simply take the SQL Server script and execute it against a database that we have created as our metastore. The SchemaTool application does also provide some functionality around updating of schemas between Hive versions, but we can handle that with some judicious use of the provided update scripts should the need arise at a later date.
We’ll be using the MSSQL scripts for creating the metastore database, which are available at:
https://github.com/apache/hive/tree/master/metastore/scripts/upgrade/mssql
In particular, the file hive-schema-2.3.0.mssql.sql which will create a version 2.3.0 metastore on Microsoft SQL Server.
Create the database
Okay first things first, we need a database. We also need a user with the required permissions on the database. It would also be nice to have a schema for holding all the created objects. This helps with transparency around what the objects relate to, should we decide to extend the database with other custom objects for other purposes, such as auditing or configuration (which would sit nicely in their own schemas). Right, that said, here’s a basic script that’ll set that up for us.
create database metastore; create login metastore with password = 'some-uncrackable-adamantium-password', default_database = metastore; use Hive; create user metastore for login metastore; go; create schema meta authorization metastore; go; grant connect to metastore; grant create table to metastore; grant create view to metastore; alter user metastore with default_schema = meta;
For simplicity I’ve named my database ‘Hive’. You can use whatever name you prefer, as we are able to specify the database name in the connection configuration.
Next of course we need to run the above hive schema creation script that we acquired from the Hive code base, in order to create the necessary database objects in the Hive metastore.
Ensure that you are logged in as the above metastore user so that the default schema above is applied when the objects are created. Execute the hive schema creation script.
The resultant schema isn’t too crazy.
You can see some relatively obvious tables created for Spark’s metadata needs. The DBS table for example lists all our databases created, and TBLS contains, yep, you guessed it, the tables and a foreign key to their related parent database record in DBS.
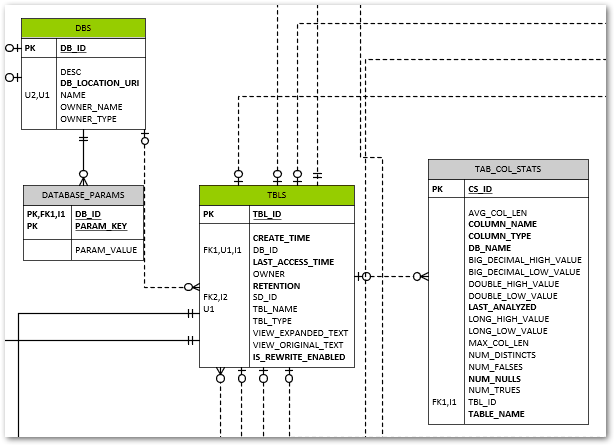
The VERSION table contains a single row that tracks the Hive metastore version (not the Hive version).
Having this visibility into the metadata used by Spark is a big benefit should you be looking to drive your various Spark-related data engineering tasks from this metadata.
Connecting to the SQL Server Hive Metastore
JDBC Driver Jar for SQL Server
One file we don’t have included as standard in the Spark code base is the JDBC driver to allow us to connect to SQL Server. We can download this from the link below.
From the downloaded archive, we need a Java Runtime Engine 8 (jre8) compatible file, and I’ve chosen mssql-jdbc-9.2.1.jre8.jar as a pretty safe bet for our purposes.
Once we have this, we need to simply copy this to the \jars directory within our Spark Home directory and we’ll have the driver available to Spark.
Configuring Spark for the Hive Metastore
Great, we have our metastore database created and the necessary driver file available to Spark for connecting to the respective SQL Server RDBMS platform. Now all we need to do is tell Spark where to find it and how to connect. There are a number of approaches to providing this, which I’ll briefly outline.
hive-site.xml
This file allows the setting of various Hive configuration parameters in xml format, including those for the metastore, which are then picked up from a standard location by Spark. This is a good vehicle for keeping local development-specific configurations out of a common code base. We’ll use this for storing the connection information such as username, password, and we’ll bundle in the jdbc driver and jdbc connection URL. A template file for hive-site.xml is provided as part of the hive binary build, which you can download at https://dlcdn.apache.org/hive/. I’ve chosen apache-hive-2.3.9-bin.tar.gz.
You’ll find a hive-site.xml.template file in the \conf subdirectory which contains details of all the configurations that can be included. It may make your head spin looking through them, and we’ll only use a very small subset of these for our configuration.
Here’s what our hive-site.xml file will end up looking like. You’ll need to fill in the specifics for your configuration parameters of course.
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>some-path\scratchdir</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>some-path\spark-warehouse</value>
<description>Spark Warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://some-server:1433;databaseName=metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>metastore</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>some-uncrackable-adamantium-password</value>
<description>password to use against metastore database</description>
</property>
</configuration>
You’ll need to copy this file to your SPARK_HOME\conf directory for this to be picked up by Hive.
Note the use of the hive.metastore.warehouse.dir setting to define the default location for our hive metastore data storage. If we create a Spark database without specifying an explicit location our data for that database will default to this parent directory.
spark-defaults.conf
This allows for setting of various spark configuration values, each of which starts with ‘spark.’. We can set within here any of the values that we’d ordinarily pass as part of the Spark Session configuration. The format is simple name value pairs on a single line, separated by white space. We won’t be making use of this file in our approach however, instead preferring to set the properties via the Spark Session builder approach which we’ll see later. Should we want to use this file, note that any Hive-related configurations would need to be prefixed with ‘spark.sql.’.
Spark Session Configuration
The third option worth a mention is the use of the configuration of the SparkSession object within our code. This is nice and transparent for our code base, but does not always behave as we’d expect. There are a number of caveats worth noting with this approach, some of which have been garnered through painful trial and error.
SparkConf.set is for Spark settings only
Seems pretty obvious when you think about it really. You can only set properties which are prefixed spark.
‘spark.sql.’ Prefix for Hive-related Configurations
As previously mentioned, just to make things clear, if we want to add any Hive settings, we need to prefix these ‘spark.sql.’
Apply Configurations to the SparkContext and SparkSession
All our SparkConf values must be set and applied to the SparkContext object with which we create our SparkSession. The same SparkConf must be used for the Builder of the SparkSession. This is shown in the code further down when we come to how we configure things on the SparkSession.
Add Thrift Server URL for Own SparkSession
The hive thrift server URL must be specified when we’re creating our own SparkSession object. This is an important point for when we want to configure our own SparkSession such as for adding the Delta OSS extensions. If you are using a provided SparkSession, such as when running PySpark from the command line, this will have been done for you and you’ll probably be blissfully unaware of the necessity of this config value. Without it however you simply won’t get a hive metastore connection and your SparkSession will not persist any metadata between sessions.
We’ll need to add the delta extensions for the SparkSession and catalog elements in order to get Delta OSS functionality.
Building on the SparkSessionUtil class that we had back in Local Development using Databricks Clusters, adding the required configurations for our hive metastore, our local SparkSession creation looks something like
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from delta import *
from pathlib import Path
DATABRICKS_SERVICE_PORT = "8787"
class SparkSessionUtil:
"""
Helper class for configuring Spark session based on the spark environment being used.
Determines whether are using local spark, databricks-connect or directly executing on a cluster and sets up config
settings for local spark as required.
"""
@staticmethod
def get_configured_spark_session(cluster_id=None):
"""
Determines the execution environment and returns a spark session configured for either local or cluster usage
accordingly
:param cluster_id: a cluster_id to connect to if using databricks-connect
:return: a configured spark session. We use the spark.sql.cerespower.session.environment custom property to store
the environment for which the session is created, being either 'databricks', 'db_connect' or 'local'
"""
# Note: We must enable Hive support on our original Spark Session for it to work with any we recreate locally
# from the same context configuration.
# if SparkSession._instantiatedSession:
# return SparkSession._instantiatedSession
if SparkSession.getActiveSession():
return SparkSession.getActiveSession()
spark = SparkSession.builder.config("spark.sql.cerespower.session.environment", "databricks").getOrCreate()
if SparkSessionUtil.is_cluster_direct_exec(spark):
# simply return the existing spark session
return spark
conf = SparkConf()
# copy all the configuration values from the current Spark Context
for (k, v) in spark.sparkContext.getConf().getAll():
conf.set(k, v)
if SparkSessionUtil.is_databricks_connect():
# set the cluster for execution as required
# Note: we are unable to check whether the cluster_id has changed as this setting is unset at this point
if cluster_id:
conf.set("spark.databricks.service.clusterId", cluster_id)
conf.set("spark.databricks.service.port", DATABRICKS_SERVICE_PORT)
# stop the spark session context in order to create a new one with the required cluster_id, else we
# will still use the current cluster_id for execution
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
return sess.builder.config("spark.sql.cerespower.session.environment", "db_connect",
conf=conf).getOrCreate()
else:
# Set up for local spark installation
# Note: metastore connection and configuration details are taken from <SPARK_HOME>\conf\hive-site.xml
conf.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
conf.set("spark.broadcast.compress", "false")
conf.set("spark.shuffle.compress", "false")
conf.set("spark.shuffle.spill.compress", "false")
conf.set("spark.master", "local[*]")
conf.set("spark.driver.host", "localhost")
conf.set("spark.sql.debug.maxToStringFields", 1000)
conf.set("spark.sql.hive.metastore.version", "2.3.7")
conf.set("spark.sql.hive.metastore.schema.verification", "false")
conf.set("spark.sql.hive.metastore.jars", "builtin")
conf.set("spark.sql.hive.metastore.uris", "thrift://localhost:9083")
conf.set("spark.sql.catalogImplementation", "hive")
conf.set("spark.sql.cerespower.session.environment", "local")
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
builder = sess.builder.config(conf=conf)
return configure_spark_with_delta_pip(builder).getOrCreate()
@staticmethod
def is_databricks_connect():
"""
Determines whether the spark session is using databricks-connect, based on the existence of a 'databricks'
directory within the SPARK_HOME directory
:param spark: the spark session
:return: True if using databricks-connect to connect to a cluster, else False
"""
return Path(os.environ.get('SPARK_HOME'), 'databricks').exists()
@staticmethod
def is_cluster_direct_exec(spark):
"""
Determines whether executing directly on cluster, based on the existence of the clusterName configuration
setting
:param spark: the spark session
:return: True if executing directly on a cluster, else False
"""
# Note: using spark.conf.get(...) will cause the cluster to start, whereas spark.sparkContext.getConf().get does
# not. As we may want to change the clusterid when using databricks-connect we don't want to start the wrong
# cluster prematurely.
return spark.sparkContext.getConf().get("spark.databricks.clusterUsageTags.clusterName", None) is not None
Note this has been updated to use the Delta OSS 1.0 library, with the handy configure_spark_with_delta_pip function.
We can test our local hive metastore is working simply by creating some objects to store therein and confirming that these are persisted across SparkSession lifetimes.
import ntpath
import posixpath
from os import path
from SparkSessionUtil import SparkSessionUtil
data_root = 'd:\dev\data'
db_name = 'test_metastore_persist'
table_name = 'test_table'
db_path = f"'{path.join(data_root, db_name)}'".replace(ntpath.sep, posixpath.sep)
spark = SparkSessionUtil.get_configured_spark_session()
spark.sql(f"""create database if not exists {db_name} location {db_path}""")
spark.sql(f"""create table if not exists {db_name}.{table_name}(Id int not null)""")
# reset our spark session
spark = None
spark = SparkSessionUtil.get_configured_spark_session()
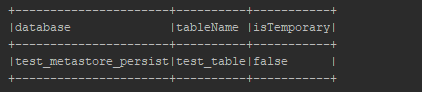
# confirm the database and table created above are available in the metastore
spark.sql(f"show tables in {db_name}").show(truncate=False)
After recreating the spark session, we see that we still have our database and table previously created. Success!
The Story So Far…
Along time ago in a gala…. no wait, stop, back up, more, more, right, thanks, that’s already been done. Right, where were we? Ah yes, so a quick summary of where we’re at with our local Spark setup and what we’ve covered off to date within this series:
- IDE integration – we’re really cooking with our code completion, support for testing frameworks, debugging, refactoring, blah de blah blah – the list goes on but you get the point. Using an IDE is hands down the way to go for the best development productivity. And productive developers are happier developers, well generally speaking anyway.
- Delta OSS functionality – bridging the gap between the data lake and data warehouse worlds. Sounds good to me.
- Our very own local hive metastore – ah bless, isn’t it cute? Even when it burps up a bit of metadata on your shoulder. Work in isolation, leverage the metadata within your code, put on your favourite Harry Belafonte album and smile.
- Work locally, unit test locally, don’t get things thrown at you for breaking shared environments. Sneer at those who don’t have the firepower of this fully armed and operational battle sta… oh no sorry, it happened again, I know, I know, I’m working on it. Okay maybe no sneering but at least feel free to be a bit smug about your databricks development endeavours.
Right so with all that said, in our next post we’ll get round to looking at some approaches to testing our code for successful Databricks deliveries.

Local Databricks Development on Windows
This post sets out steps required to get your local development environment setup on Windows for databricks. It includes setup for both Python and Scala development requirements. The intention is to allow you to carry out development at least up to the point of unit testing your code. Local databricks development offers a number of obvious advantages. With Windows being a popular O/S for organisations’ development desktops it makes sense to consider this setup. Considerations for cost reduction, developing offline, and, at least for minimal datasets, faster development workflow as network round-tripping is removed, all help. Right, with that said, let’s take a look at what we need to get started. I’ll split things into core requirements, just Python, just Scala, and Python and Scala, to cover off the main development scenarios. Apologies in advance to R users as not being an R user I won’t be covering this.
Core Requirements
Install WinUtils
This is a component of the Hadoop code base that is used for certain Windows file system operations and is needed for Spark to run on Windows. You can read about how to compile your own version from the Hadoop code base, or acquire a precompiled version, in my post on the subject here. I’ll skip to the point where you have the compiled code, either from downloading from GitHub precompiled, or by compiling from source.
Which version of WinUtils?
Spark can be built against various versions of Hadoop, and adopts a naming convention in its tar or zip archive that includes both the Spark version and Hadoop version, ‘Spark-<spark-version>-<bin/src>-hadoop<hadoop-version>.tgz‘, e.g. Spark-3.1.2-bin-hadoop3.2.tgz. If you are planning on using the PySpark python package for development you will need to use the version of Hadoop that is included.
On non-windows environments you can choose which version of Hadoop to include with your PySpark by setting the PYSPARK_HADOOP_VERSION environment variable prior to calling ‘pip install pyspark=<version>’, however this doesn’t appear to work for Windows, forcing you to use the default version of Hadoop for the package. For PySpark 3.1.2, this is Hadoop 3.2. For those interested, further information on hadoop version-specific installs of PySpark on non-windows systems is available at https://spark.apache.org/docs/latest/api/python/getting_started/install.html.
As we’re on Windows, we’ll go with our PySpark 3.1.2. and Hadoop 3.2, which means we need WinUtils from the Hadoop 3.2 build.
Precompiled Code
Simply copy this to a local folder, e.g. D:\Hadoop\WinUtils, and make a note of the ‘\bin‘ subdirectory which contains the winutils.exe file.
Own Compiled Code
If you’ve built your own winutils.exe, you’ll need to create a \bin directory to house, e.g. D:\Hadoop\WinUtils\bin and copy winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files here.
Environment Variables
HADOOP_HOME
You then need to add an environment variable ‘HADOOP_HOME‘ for Spark to understand where to find the required Hadoop files. You can do this using the following powershell:
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'D:\Hadoop\winutils', [System.EnvironmentVariableTarget]::Machine)
Note: This needs to be the name of the parent of the bin directory, with no trailing backslash.
As environment variables are initialised on startup of terminals, IDEs etc, any that are already open will need to be reopened in order to pick up our ‘HADOOP_HOME‘.
Path
We’ll also need to add the path to the bin directory to our Path variable, if we want to invoke ‘winutils’ from the command line without using the full path to the .exe file. The following is based on a path of D:\Hadoop\winutils\bin for our winutils.exe.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Hadoop\winutils\bin;", [System.EnvironmentVariableTarget]::Machine)
Java JDK
Spark requires Java 1.8 to run. It won’t run with later versions, so we need to be specific here. You can download either the Oracle SE JDK here, or the OpenJDK here. Please note the change in the licencing agreement if opting for Oracle SE and using in commercial development.
Run the installer, following the desired options and make a note of your installation path.
Environment Variables
JAVA_HOME
This should have been set by the installer and will point to the root of your JDK installation.
Path (Optional)
This will make the various executables within the JDK accessible without requiring an explicit path, something of use for any future Java development. It is not required for our Spark installation purposes but I’ve included this for completeness here should you want to use these.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Java\jdk1.8.0_191\bin;", [System.EnvironmentVariableTarget]::Machine)
Okay, that’s us done with the core requirements parts. Now onto the development scenario specifics.
Python-Only Development
Install Anaconda
This is my preferred option for getting Python setup for data development. Local databricks development can involve using all manner of python libraries alongside Spark. Anaconda makes managing Python environments straight forward and comes with a wide selection of packages in common use for data projects already included, saving you having to install these. You can run Spark without this if you prefer, you’ll just have to download Python (recommended 3.7 but min. 3.5 for Windows) and configure environments using the Python native tools for this, none of which is particularly difficult. I won’t cover that approach here as this is easily done with the help of a quick Google search.
You can download Anaconda for Windows here.
New Python Environment (Optional)
It may make sense to create a separate environment for your Spark development. You can if you prefer simply use the ‘base’ environment, else you can create your own via either the Anaconda prompt or the Anaconda Navigator. Both are well documented and so again I won’t be detailing here. I’ve created a ‘pyspark’ environment for this purpose. If you do create a new environment make sure that you activate this for any Python steps that follow. This is something often missed if you are not familiar with working with Python environments.
Install PySpark
Using either the Anaconda prompt or Anaconda Navigator install the pyspark package. Due to a compatibility issue with the latest delta.io code and Spark 3.1, if you are intending on using databricks Delta (see below), the latest version you can specify is version 3.0.0 rather than the current 3.1.1 version. This issue exists only with the OSS version of the Delta code base and not with the databricks commercial offering.
Note: The pyspark package includes all required binaries and scripts for running Spark (except the WinUtils files noted above required for Windows). It is not required to download Spark separately for local databricks development if using pyspark.
Scala-Only Development
If you have no Python installation and want to develop using only Scala, then you will need to take a slightly different approach to running Spark.
Note: Before considering Scala only, if you are planning on using Databricks Connect be aware that you will need to have Python installed, so your better option will probably be as outlined in the ‘Python and Scala Development’ section below.
Install Spark
Without pyspark installed, for local databricks development you’ll need to download the required Spark binaries, which can be done here. You can choose either the download with or that without Hadoop for our purposes, either is fine. The main difference between these is the inclusion of about 70MB of additional jars in the \jars directory for the Hadoop download. Extract these to a directory of your choosing such as D:\Spark. We’ll need to add some environment variables as below, so for now make a note of the directory chosen and we’re done for now.
Scala Development Environment
We won’t cover how to setup the Scala environment itself. You can find details here for the Intellij IDE, or here for VSCode, which uses the ‘Metals’ language server. You can also simply install the Scala binaries, the latest version of which are available here, and then use the command line. You can find instructions here if required.
Python and Scala Development
If you are developing in both Python and Scala, not uncommon if you have both ‘Data Engineer’ and ‘Data Scientist’ aspects to your work, you will not need all the steps outlined above for ‘Scala-Only Development’. Follow the Python-Only steps, which will install Spark via the pyspark Python package, and then simply setup your development environment as mentioned in the ‘Scala-Only Development – Scala Development Environment’ section above.
Spark Environment Variables
Depending on whether you have used the pyspark Python package to provide the Spark binaries for your local databricks development, or whether you have downloaded Spark separately, you will need to amend the following based on the destination of your files.
SPARK_HOME
This should be set to the root of the Spark files. For pyspark, you will find the package installed to either <PathToAnaconda>\Lib\site-packages\pyspark, e.g. D:\Anaconda3\Lib\site-packages\pyspark, if you are using the ‘base’ environment, or if you have created your own environment you’ll find the default path at <PathToAnaconda>\Envs\<EnvName>\Lib\site-packages\pyspark. Amend the following powershell accordingly.
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('SPARK_HOME', 'D:\Anaconda3\envs\pyspark\Lib\site-packages\pyspark', [System.EnvironmentVariableTarget]::Machine)
Path
The following will need to be added to your path in order to run the various Spark commands from the command line:
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
Here’s some powershell I made earlier…
# Append required pyspark paths to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};${env:SPARK_HOME}\bin;${env:SPARK_HOME}\sbin;", [System.EnvironmentVariableTarget]::Machine)
Add Databricks Delta Libraries
The databricks Delta libraries for Spark add some fantastic functionality to Spark SQL and are very much revolutionising data lakes and data warehousing with their ‘LakeHouse‘ architecture. You can read all about Delta here. Suffice to say that these libraries will probably feature in your local databricks development.
Note that there are actually two different development streams for Delta. One is that used on the commercial databricks service, The other is that made Open Source at the previous link, which we’ll be using. I’ll refer to this as Delta OSS to avoid confusion.
Known Issue with Delta OSS 0.8.0 and Spark 3.1
Unfortunately there is an issue with using Delta OSS 0.8.0 with Spark 3.1. The setting of the Spark configuration ‘spark.sql.catalog.spark_catalog‘ to ‘org.apache.spark.sql.delta.catalog.DeltaCatalog‘ will result in an error that prevents using Delta. Some users have suggested simply omitting setting this configuration value, however this then causes further headaches when working with delta tables. You’ll get errors relating to the table metadata, such as ‘Cannot write nullable values to non-null column <colName>‘, and errors trying to cast values to dates and all sorts of other woes. These errors only really hint at what might be up, which appears to be the lack of the DeltaCatalog required for correct table metadata storage. The only real solution is to use Spark 3.0 with Delta OSS, which for local development should not be an issue. I’m told this issue should be resolved in Spark 3.2. As previously mentioned, there is no issue with the commercial offering available on the databricks platform, only with the Delta OSS code.
You can read the quickstart guide at delta.io here to see how we can use the Delta libraries for the various ways of working locally you may have adopted. I’ll include the Python and Scala ones here for completeness.
Delta-Spark 1.0.0 PyPI Package
With the version 1.0.0 release of Delta OSS we now have a PyPI package available. This is great news. We can now use pip to install the package as below:
pip install delta-spark=1.0.0
This will install the Python wrappers for Delta OSS but will not include the related Scala jar files that are the core of the code base. The jars will be fetched at runtime as described below:
Acquiring the Scala Library and Enabling the Delta OSS Functionality
Delta OSS 0.8.0
Python
Add the following code to your Spark session configuration
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.jars.packages", "io.delta:delta-core_2.12:0.8.0") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
from delta.tables import *
The ‘spark.jars.packages‘ link will cause the jar files to be downloaded from Maven and stored in your local Ivy package store, the default location being .ivy2\jars within your user home directory.
Including the Libraries for Development
If you open up the io.delta_delta-core_2.12-0.8.0.jar archive file (any zip program should do) you will see that there is also a Python file included, delta\tables.py.

This contains the python code for interfacing with the underlying Scala implementation. With the jar added to your Spark session you are then able to import the Python module ‘delta\tables.py‘ and add Delta table functionality to your efforts.
Code Completion/Linting in PyCharm
Pycharm won’t recognise the tables.py file that is contained in the jar, as it is only visible to Spark at runtime. The delta code base is not available as a Python package and so cannot be ‘installed’ to Python and easily recognised by PyCharm. In order to have fully functional code completion you will need to download the source code and add the required path to the project structure as a ‘Content Root’ so that it is visible. You can download the required release for your local databricks development from GitHub here. Unzip it to a suitable location locally and within PyCharm, in File | Settings | Project: <projectName> | Project Structure, add the python\delta folder as a ‘Content Root’ as shown below.

By using the above ‘from delta.tables import *‘ you will then have Delta code completion within your PyCharm environment.
Delta OSS 1.0.0
With the release of the PyPI package for delta-spark, we have none of the above hoops to jump through to get our Delta OSS code working in Python. As it is available in our virtual environment, we can simply import the required modules and code completion/Linting will be available to our IDE. Happy days. We do however still need to acquire the Scala library and enable the required functionality. The Spark Session configuration is very similar to that for Delta OSS 0.8.0 above, with the added bonus of a handy utility function ‘configure_spark_with_delta_pip’ to ensure that we grab the correct Scala jar file without hard coding the version. Pass in your configured Spark Session Builder object, and this will add the ‘spark.jars.packages‘ configuration value for the required jar that we had to add ourselves in 0.8.0.
# delta-spark 1.0.0 brings a handy configuration function for acquiring the Scala jars...
spark = configure_spark_with_delta_pip(
pyspark.sql.SparkSession.builder.appName("MyApp")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
).getOrCreate()
from delta.tables import *
Add the jar file to PySpark
If you are using the PySpark package to provide your local Spark code base, as opposed to downloading the Spark code and installing to a local directory, you’ll need to add the required delta-core jar file to your PySpark\jars folder. Simply copy this from the .ivy location above and you’re done.
Scala
Maven
Add the following to your Maven pom file:
<dependency> <groupId>io.delta</groupId> <artifactId>delta-core_2.12</artifactId> <version>0.8.0</version> </dependency>
Note: Change your version accordingly to whatever version of Delta OSS you are using.
SBT
If using SBT, you can simply add the following to your build.sbt file:
libraryDependencies += "io.delta" %% "delta-core" % "0.8.0"
Note: Change your version accordingly to whatever version of Delta OSS you are using.
You now have Delta functionality within your locally developed Spark code. Smokin’…
And We’re Good To Go…
We now have our local databricks development environment setup on Windows to allow coding against Spark and Delta. This won’t necessarily serve all your needs, with aspects like integration testing probably falling out of scope. It should however remove the need to always have clusters up, reduce disruption that would be caused on a shared development environment, as well as increasing productivity during development. Personally I find it well worth setting up and hope you will find considerable benefits from this way of working.
In the next post we’ll be looking at hooking up databricks connect with your local dev tools for when you need to run against a databricks cluster. Thanks for reading and see you soon.

Build Your Own WinUtils for Spark
The option of setting up a local spark environment on a Windows build, whether for developing spark applications, running CI/CD activities or whatever, brings many benefits for productivity and cost reduction. For this to happen however, you’ll need to have an executable file called winutils.exe. This post serves to supplement the main thread of the series on Development on Databricks, making a stop at C++ world (don’t panic!) as we handle the situation where you are required to build your own WinUtils executable for use with Spark. It is intended for an audience unfamiliar with building C++ projects, and as such seasoned C++ developers will no doubt want to skip some of the ‘hand-holding’ steps.
What Does Spark Need WinUtils For?
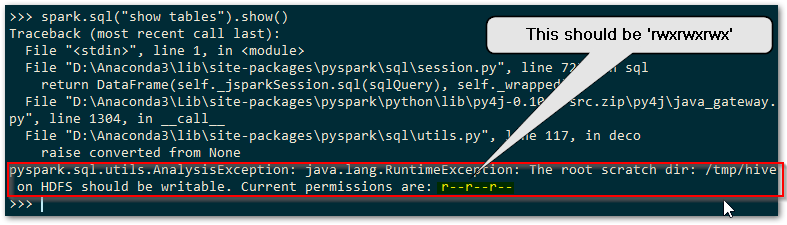
In order to run Apache Spark locally, it is required to use an element of the Hadoop code base known as ‘WinUtils’. This allows management of the POSIX file system permissions that the HDFS file system requires of the local file system. If Spark cannot find the required service executable, WinUtils.exe, it will throw a warning as below, but will proceed to try and run the Spark shell.

Spark requires that you have set POSIX compatible permissions for a temporary directory used by the Hive metastore, which defaults to C:\tmp\hive (the location of this can be changed as described here ). In order to set these POSIX permissions you need to use WinUtils, and without these permissions being set correctly any attempt to use Spark SQL to access the Hive metastore will fail. You’ll get an error complaining about lack of writable access to the above scratch directory and Spark will throw a full blown sulk like a kid deprived of their Nintendo Switch. Here’s a sulk it threw earlier…
You’ll need to use WinUtils as below in order to set the POSIX permissions for HDFS that the Hive metastore will be happy with.
# set the rwxrwxrwx POSIX permissions winutils chmod -R 777 c:\tmp\hive
So if you’re on Windows and want to run Spark, WinUtils is a necessity to get going with anything involving the Hive metastore.
Why Build Your Own?
Existing Prebuilt WinUtils Repositories
There are GitHub repositories that are independently maintained, available here, with a previous one here (no longer maintained) that contains the compiled exe file and any supporting libraries, for the various versions of the Hadoop code base included within Apache Spark. If you don’t need to provide transparency of the source of the code used you can always simply grab the compiled files for local use rather than going to the trouble of compiling your own.
The maintainer of the second compiled WinUtils repo above details the process that they go to in order to ensure that the code is compiled from the legitimate source, with no routes for malware to infiltrate. This may however still not be acceptable from a security perspective. The security administrators and custodians of your systems will quite probably have tight controls on you simply copying files whose originating source code cannot be verified 100%, for obvious reasons. We all know the perils of simply downloading and running opaque executables and so the option to build your own winutils executable for Spark will be welcome.
Compiling from Source
WinUtils is included within the main Apache Spark GitHub repository, with all dependent source code available for inspection as required. As you can see from the repo, the Hadoop code base is huge, but the elements we really need are only a small fraction of this. Getting the whole Hadoop code base to build on a Windows machine is no easy task, and we won’t be trying this here. You’ll need a very specific set of dependent components and a dedicated build machine if you want to build the full Hadoop repo, which is the approach taken in the above prebuilt repos. You can find a number of tutorials on how to do this on the web, such as the one found here. Note the specific components required based on the code base. For our purposes we can focus on just the WinUtils code itself. I’ll be using the ‘branch-3.2’ branch for this exercise.
So having cloned/downloaded the Apache Hadoop repo and checked out to the ‘branch-3.2’, the desired WinUtils code can be found within our local repo at
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\winutils
and
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native
You’ll notice that the above code is written in C/C++, and so if we’re going to build the executable we need to be able to compile C/C++ code. No great surprises there. I should probably confess at this point that I haven’t touched C++ for a good few years to any advanced degree, so I’m far removed from being a C++ developer these days and am going to simplify things here (to avoid confusing me and possibly you).
Tools for the Job
If you have Visual Studio installed you can simply extend the Features to include C++ desktop applications, thereby gaining the required compiler, linker etc. If you don’t have Visual Studio, you can still get the Build Tools as a separate download, available here for VS2019. Once you have the required tools, we can look at what is required to build your own WinUtils executable.
Building the Code
Cue trumpets… pap pap pap pap paaaaeeeerrrrr…. oh hold on, there’s still a little way to go. Trumpets, come back in a bit, grab a coffee, play some Uno or something, won’t be long, nearly there.
Desired Output
In the latest version of the WinUtils code, there are two projects in the WinUtils directory. One is for the WinUtils.exe used directly from Spark on Windows, and the other is for a library, libwinutils.lib, that will be referenced from WinUtils.exe. If you look at the precompiled repos mentioned above, for each version of Hadoop you’ll see a number of files that are output in addition to the two previously mentioned. We’ll be needing the hadoop.dll and hadoop.lib files for our purposes of running Spark on Windows. We don’t need the hdfs.*, mapred.* or yarn.* files as these components of Hadoop won’t be of interest.
We want to be able to compile both the winutils, libwinutils and native projects and make use of the resultant files. If you are not familiar with building code using Microsoft Visual Studio and associated tooling, these files will be generated in a default output location such as winutils\debug or winutils\Release, depending on the configuration chosen (more on that below). Okay, with that end goal in mind, let’s look to building the code.
Retarget Projects with Visual Studio
The projects are based on the VS2010 IDE, so you’ll get upgrade messages when opening if you are on a later version.
Assuming you are on a later Windows build than Windows 8.1, you will need to change the Build tools and Windows SDK targeted by the solution projects. The first time you open the winutils.sln or native.sln files you will be greeted with the following dialogue and should choose whatever is the latest installed on your system. For me this was v142 as I’m on Visual Studio 2019, and SDK 10.0.19041.0.
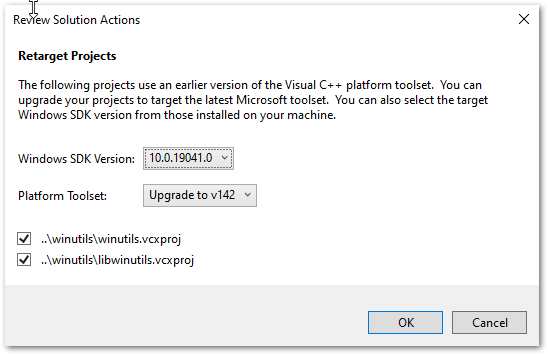
WinUtils Solution Code Amendments Required
Okay, so we’ve grabbed the code base and installed the required tools to build the code. There are a couple of things that need to be considered for a successful build of your own WinUtils for Spark.
libwinutils.c Issues?
You’ll see the following errors in the libwinutils.c source file, which imply an issue with the code.

However, the issue is actually with the lack of values for the preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE.
WSCE Preprocessor Directive Values
The preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE can be seen defined within the winutils and libwinutils projects, as the project file excerpt below shows.

Notice that they are populated from parameters passed in to the build, as denoted by the WSCE_CONFIG_DIR=$(WsceConfigDir) syntax. So when building the winutils project it expects these values to be passed in. Right, time to find what values are used in the Hadoop code base to see the relevance of this…
Values from Maven Pom Files
In order to understand what parameters are required to be passed to the build, we need to take a look at the Maven pom file that is used to build this part of the code base, found at
\hadoop-trunk\hadoop-common-project\hadoop-common\pom.xml
Firstly, at the top of the file, we see the following properties defined:


The various parameters passed define the configuration, platform, output directories etc, and also the two expected values, WsceConfigDir, and WsceConfigFile that will feed the preprocessor directives mentioned. These are taken from the property references ${wsce.config.dir} and ${wsce.config.file} respectively. The values for these are supplied, as we’ve just seen, in the property definitions at the top of the pom file. Right, glad we cleared that one up.
For context, these values are used as part of the Yarn Secure Containers setup, which you can read about here. We’ll need to ensure that these values are passed in for each of our build methods detailed below. As we won’t actually be using the Yarn elements for our purposes of running local Spark, we don’t need to concern ourselves with the directory and file in question not being available. We can pass empty strings, “”, for each if we want, use the values from the pom file, or use other string values. I’m going to stick with the pom file values for this exercise.
The code within the hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native folder that creates the hadoop.dll and hadoop.lib files requires no amendment and should compile without issue.
Building the WinUtils Solution with Visual Studio
Add Preprocessor Directives
On the winutils Poject Properties dialogue, choose your required Configuration. In the Configuration Properties | C/C++ | Preprocessor | Preprocessor Definitions select ‘Edit…’ to amend the values, as shown below:
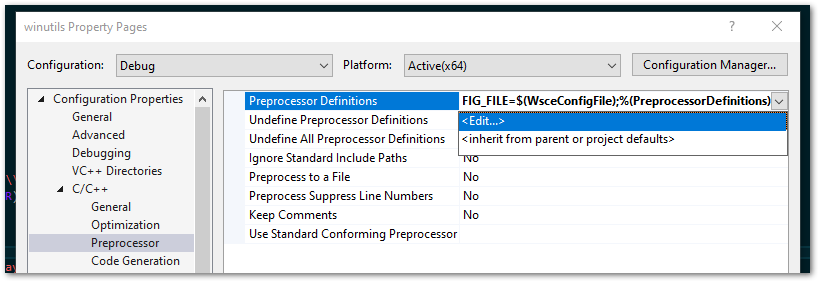
You’ll see the evaluated values in the second box. I’ve edited one below to show this taking effect. Notice that WSCE_CONFIG_FILE is still undefined as far as Visual Studio is concerned. This will also need to have a value as well as mentioned above.
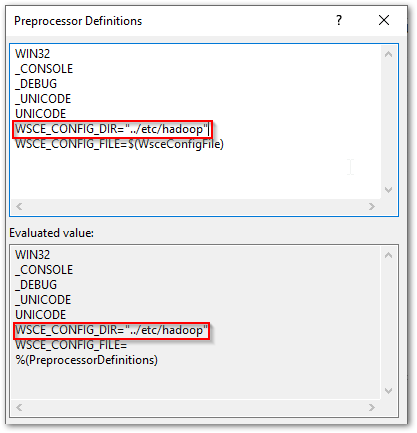
Do the same for the libwinutils project.
Issues Building on x64 Windows
By default, the original projects are configured to build against the x86 Windows platform. If you try and build using this on a x64 Windows machine, you will probably encounter the error below.

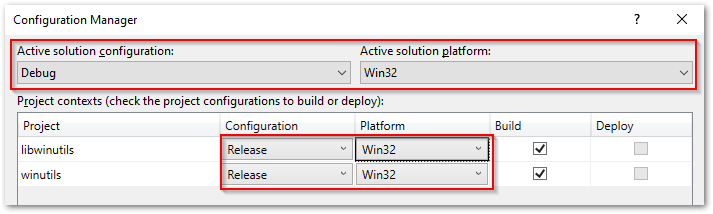
This can throw you off the scent a little as to the real issue here. You have the build tools installed as part of the Visual Studio setup for C++ projects, so why all the belly aching? Well, you’ll need to change the project configurations to build vs x64, as the build tools you have installed will be for this architecture.
If you are on x64 Windows, be sure to change the project configurations so that they build against the x64 rather than x86 platform, to avoid the issue mentioned above. This is done from Build | Configuration Manager… as shown below:
Build Your Solution
Right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B, and this will build first the libwinutils project (a dependency of winutils) and then the winutils project, to the output directories expected for your configuration.
Building the WinUtils Solution with MSBuild
Opening up a ‘Developer Command Prompt for Visual Studio’, you’ll have access to MSBuild from the command line. If you have added the path to MSBuild.exe to your ‘Path’ environment variable you will have access to this also from a regular command prompt. Navigate to your winutils solution directory.
As with the Visual Studio method, you’ll need to specify the correct platform if you are on x64, as it will default to an x86 build. Otherwise, you’ll get the same error as shown in the Visual Studio section above regarding missing build tools. It would be nice if MSBuild defaulted to use the same platform as the tooling for your installation. A simple parameter addition is all that is required to sort this.
In addition, add the parameters as defined in the Maven pom file , resulting in the MSBuild command as below:
rem output for the build will be to the winutils\bin directory MSBuild winutils.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\Winutils\ /p:WsceCOnfigDir="../etc/config" /p:WsceConfigFile="wsce-site.xml"
Execute this from the winutils solution directory to ensure the relative paths are as desired. You outputs will be built and output to the winutils\bin directory specified.
Building the Native Solution with Visual Studio
As mentioned, there are no code amendments required for the native.sln file that creates hadoop.dll and hadoop.lib. You will however need to change the configuration to x64 as necessary, as per ‘Issues Building on x64 Windows’ above. Once that is done, right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B and your code will be output to the respective debug or release folders.
Building the Native Solution with MSBuild
Follow the above ‘Building the WinUtils Solution with MSBuild’, navigating instead to the native solution directory and substituting the following MSBuild command.
rem output for the build will be to the native\bin directory MSBuild native.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\native\"
You outputs will be built and output to the native\bin directory specified.
A Build of Our Very Own WinUtils for Spark
Well technically not really ‘ours’, as those nice dedicated Hadoop developers did all the real work, but anyway. So now you have a build of your own winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files for winutils from known source code. This ticks those security checkboxes nicely. Bring the trumpeters back in…yay! Oh, they’ve gone home, never mind, improvise. Woop woop, papapapapa etc. etc. Take a bow.
Using Your WinUtils Executable
Destination Directory
In order for Spark to use the WinUtils executable, you should create a local directory with a ‘\bin’ subdirectory as suggested below:
D:\Hadoop\winutils\bin
Copy the winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files files generated earlier to this destination.
Environment Variables
HADOOP_HOME
You then need to add an environment variable ‘HADOOP_HOME’ for Spark to understand where to find the required Hadoop files. You can do this using the following powershell:
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'D:\Hadoop\winutils', [System.EnvironmentVariableTarget]::Machine)
Note: This needs to be the name of the parent of the bin directory, with no trailing backslash.
As environment variables are initialised on startup of terminals, IDEs etc, any that are already open will need to be reopened in order to pick up our ‘HADOOP_HOME’.
Path
We’ll also need to add the path to the bin directory to our Path variable, if we want to invoke ‘winutils’ from the command line without using the full path to the .exe file.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Hadoop\winutils\bin;", [System.EnvironmentVariableTarget]::Machine)
With that done we are all set to use this with our local Spark installation.
Signing Off…
Something of a diversion from the general world of data analytics this time, but for those who need to run Spark on Windows with no awkward questions about where that exe came from, this article should be of benefit. In the next post in this series we’ll look at setting up Spark locally, something that is not half as scary as it sounds. It is also at least twice as useful as you might initially think, maybe even three times. Till next time.



