
The Hive MetaStore and Local Development
- Development on Databricks
- Beyond Databricks Notebook Development
- Build Your Own WinUtils for Spark
- Local Databricks Development on Windows
- Local Development using Databricks Clusters
- The Hive MetaStore and Local Development
In this next post in our series focussing on Databricks development, we’ll look at how to create our own Hive metastore locally using SQL Server, and wire it up for the use of our development environment. Along the way we’ll dip into a few challenges with getting this running with your own projects and how to overcome them. This should provide us with our final element of our local Spark environment for Databricks development.
The Hive Metastore
Part of the larger Apache Hive data warehouse platform, the Hive metastore is a repository for details relating to Hive databases and their objects. It is adopted by Spark as the solution for storage of metadata regarding tables, databases and their related properties. An essential element of Spark, it is worth getting to know this better so that it can be safeguarded and leveraged for development appropriately.
Hosting the Hive Metastore
The default implementation of the Hive metastore in Apache Spark uses Apache Derby for its database persistence. This is available with no configuration required but is limited to only one Spark session at any time for the purposes of metadata storage. This obviously makes it unsuitable for use in multi-user environments, such as when shared on a development team or used in Production. For these implementations Spark platform providers opt for more robust multi-user ACID-compliant relational database product for hosting the metastore. Databricks opts for Azure SQL Database or MySQL and provides this preconfigured for your workspace as part of the PaaS offering.
Hive supports hosting the metastore on Apache Derby, Microsoft SQL Server, MySQL, Oracle and PostgreSQL.
SQL Server Implementation
For our local development purposes, we’ll walk through hosting the metastore on Microsoft SQL Server Developer edition. I won’t be covering the installation of SQL Server as part of this post as we’ve got plenty to be blabbering on about without that. Please refer to the Microsoft Documentation or the multitude of articles via Google for downloading and installing the developer edition (no licence required).
Thrift Server
Hive uses a service called HiveServer for remote clients to submit requests to Hive. Using Apache Thrift protocols to handle queries using a variety of programming languages, it is generally known as the Thrift Server. We’ll need to make sure that we can connect to this in order for our metastore to function, even though we may be connecting on the same machine.
Hive Code Base within Spark
Spark includes the required Hive jars in the \jars directory of your Spark install, so you won’t need to install Hive separately. We will however need to take a look at a few of the files provided in the Hive code base to help with configuring Spark with the metastore.
Creating the Hive Metastore Database
It is worth mentioning at this point that, unlike Spark, there is no Windows version of Hive available. We could look to running via Cygwin or Windows Subsystem for Linux (WSL) but we don’t actually need to be running Hive standalone so no need. We will be creating a metastore database on a local instance of SQL Server and pointing Spark to this as our metadata repository. Spark will use its Hive jars and the configurations we provide and everything will play nicely together.
The Hive Metastore SchemaTool
Within the Hive code base there is a tool to assist with creating and updating of the Hive metastore, known as the ‘SchemaTool‘. This command line utility basically executes the required database scripts for a specified target database platform. The result is a metastore database with all the objects needed by Hive to track the necessary metadata. For our purposes of creating the metastore database we can simply take the SQL Server script and execute it against a database that we have created as our metastore. The SchemaTool application does also provide some functionality around updating of schemas between Hive versions, but we can handle that with some judicious use of the provided update scripts should the need arise at a later date.
We’ll be using the MSSQL scripts for creating the metastore database, which are available at:
https://github.com/apache/hive/tree/master/metastore/scripts/upgrade/mssql
In particular, the file hive-schema-2.3.0.mssql.sql which will create a version 2.3.0 metastore on Microsoft SQL Server.
Create the database
Okay first things first, we need a database. We also need a user with the required permissions on the database. It would also be nice to have a schema for holding all the created objects. This helps with transparency around what the objects relate to, should we decide to extend the database with other custom objects for other purposes, such as auditing or configuration (which would sit nicely in their own schemas). Right, that said, here’s a basic script that’ll set that up for us.
create database metastore; create login metastore with password = 'some-uncrackable-adamantium-password', default_database = metastore; use Hive; create user metastore for login metastore; go; create schema meta authorization metastore; go; grant connect to metastore; grant create table to metastore; grant create view to metastore; alter user metastore with default_schema = meta;
For simplicity I’ve named my database ‘Hive’. You can use whatever name you prefer, as we are able to specify the database name in the connection configuration.
Next of course we need to run the above hive schema creation script that we acquired from the Hive code base, in order to create the necessary database objects in the Hive metastore.
Ensure that you are logged in as the above metastore user so that the default schema above is applied when the objects are created. Execute the hive schema creation script.
The resultant schema isn’t too crazy.
You can see some relatively obvious tables created for Spark’s metadata needs. The DBS table for example lists all our databases created, and TBLS contains, yep, you guessed it, the tables and a foreign key to their related parent database record in DBS.
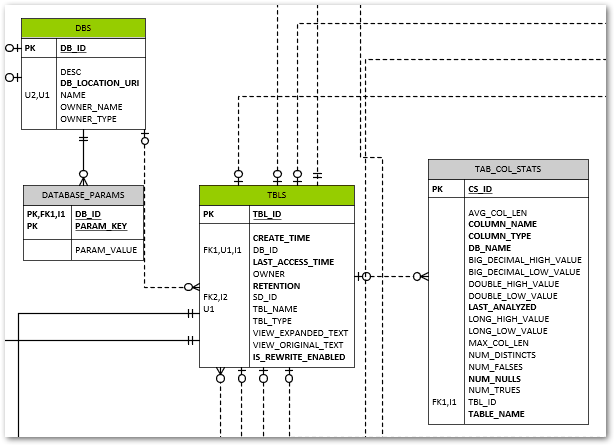
The VERSION table contains a single row that tracks the Hive metastore version (not the Hive version).
Having this visibility into the metadata used by Spark is a big benefit should you be looking to drive your various Spark-related data engineering tasks from this metadata.
Connecting to the SQL Server Hive Metastore
JDBC Driver Jar for SQL Server
One file we don’t have included as standard in the Spark code base is the JDBC driver to allow us to connect to SQL Server. We can download this from the link below.
From the downloaded archive, we need a Java Runtime Engine 8 (jre8) compatible file, and I’ve chosen mssql-jdbc-9.2.1.jre8.jar as a pretty safe bet for our purposes.
Once we have this, we need to simply copy this to the \jars directory within our Spark Home directory and we’ll have the driver available to Spark.
Configuring Spark for the Hive Metastore
Great, we have our metastore database created and the necessary driver file available to Spark for connecting to the respective SQL Server RDBMS platform. Now all we need to do is tell Spark where to find it and how to connect. There are a number of approaches to providing this, which I’ll briefly outline.
hive-site.xml
This file allows the setting of various Hive configuration parameters in xml format, including those for the metastore, which are then picked up from a standard location by Spark. This is a good vehicle for keeping local development-specific configurations out of a common code base. We’ll use this for storing the connection information such as username, password, and we’ll bundle in the jdbc driver and jdbc connection URL. A template file for hive-site.xml is provided as part of the hive binary build, which you can download at https://dlcdn.apache.org/hive/. I’ve chosen apache-hive-2.3.9-bin.tar.gz.
You’ll find a hive-site.xml.template file in the \conf subdirectory which contains details of all the configurations that can be included. It may make your head spin looking through them, and we’ll only use a very small subset of these for our configuration.
Here’s what our hive-site.xml file will end up looking like. You’ll need to fill in the specifics for your configuration parameters of course.
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>some-path\scratchdir</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>some-path\spark-warehouse</value>
<description>Spark Warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://some-server:1433;databaseName=metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>metastore</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>some-uncrackable-adamantium-password</value>
<description>password to use against metastore database</description>
</property>
</configuration>
You’ll need to copy this file to your SPARK_HOME\conf directory for this to be picked up by Hive.
Note the use of the hive.metastore.warehouse.dir setting to define the default location for our hive metastore data storage. If we create a Spark database without specifying an explicit location our data for that database will default to this parent directory.
spark-defaults.conf
This allows for setting of various spark configuration values, each of which starts with ‘spark.’. We can set within here any of the values that we’d ordinarily pass as part of the Spark Session configuration. The format is simple name value pairs on a single line, separated by white space. We won’t be making use of this file in our approach however, instead preferring to set the properties via the Spark Session builder approach which we’ll see later. Should we want to use this file, note that any Hive-related configurations would need to be prefixed with ‘spark.sql.’.
Spark Session Configuration
The third option worth a mention is the use of the configuration of the SparkSession object within our code. This is nice and transparent for our code base, but does not always behave as we’d expect. There are a number of caveats worth noting with this approach, some of which have been garnered through painful trial and error.
SparkConf.set is for Spark settings only
Seems pretty obvious when you think about it really. You can only set properties which are prefixed spark.
‘spark.sql.’ Prefix for Hive-related Configurations
As previously mentioned, just to make things clear, if we want to add any Hive settings, we need to prefix these ‘spark.sql.’
Apply Configurations to the SparkContext and SparkSession
All our SparkConf values must be set and applied to the SparkContext object with which we create our SparkSession. The same SparkConf must be used for the Builder of the SparkSession. This is shown in the code further down when we come to how we configure things on the SparkSession.
Add Thrift Server URL for Own SparkSession
The hive thrift server URL must be specified when we’re creating our own SparkSession object. This is an important point for when we want to configure our own SparkSession such as for adding the Delta OSS extensions. If you are using a provided SparkSession, such as when running PySpark from the command line, this will have been done for you and you’ll probably be blissfully unaware of the necessity of this config value. Without it however you simply won’t get a hive metastore connection and your SparkSession will not persist any metadata between sessions.
We’ll need to add the delta extensions for the SparkSession and catalog elements in order to get Delta OSS functionality.
Building on the SparkSessionUtil class that we had back in Local Development using Databricks Clusters, adding the required configurations for our hive metastore, our local SparkSession creation looks something like
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from delta import *
from pathlib import Path
DATABRICKS_SERVICE_PORT = "8787"
class SparkSessionUtil:
"""
Helper class for configuring Spark session based on the spark environment being used.
Determines whether are using local spark, databricks-connect or directly executing on a cluster and sets up config
settings for local spark as required.
"""
@staticmethod
def get_configured_spark_session(cluster_id=None):
"""
Determines the execution environment and returns a spark session configured for either local or cluster usage
accordingly
:param cluster_id: a cluster_id to connect to if using databricks-connect
:return: a configured spark session. We use the spark.sql.cerespower.session.environment custom property to store
the environment for which the session is created, being either 'databricks', 'db_connect' or 'local'
"""
# Note: We must enable Hive support on our original Spark Session for it to work with any we recreate locally
# from the same context configuration.
# if SparkSession._instantiatedSession:
# return SparkSession._instantiatedSession
if SparkSession.getActiveSession():
return SparkSession.getActiveSession()
spark = SparkSession.builder.config("spark.sql.cerespower.session.environment", "databricks").getOrCreate()
if SparkSessionUtil.is_cluster_direct_exec(spark):
# simply return the existing spark session
return spark
conf = SparkConf()
# copy all the configuration values from the current Spark Context
for (k, v) in spark.sparkContext.getConf().getAll():
conf.set(k, v)
if SparkSessionUtil.is_databricks_connect():
# set the cluster for execution as required
# Note: we are unable to check whether the cluster_id has changed as this setting is unset at this point
if cluster_id:
conf.set("spark.databricks.service.clusterId", cluster_id)
conf.set("spark.databricks.service.port", DATABRICKS_SERVICE_PORT)
# stop the spark session context in order to create a new one with the required cluster_id, else we
# will still use the current cluster_id for execution
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
return sess.builder.config("spark.sql.cerespower.session.environment", "db_connect",
conf=conf).getOrCreate()
else:
# Set up for local spark installation
# Note: metastore connection and configuration details are taken from <SPARK_HOME>\conf\hive-site.xml
conf.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
conf.set("spark.broadcast.compress", "false")
conf.set("spark.shuffle.compress", "false")
conf.set("spark.shuffle.spill.compress", "false")
conf.set("spark.master", "local[*]")
conf.set("spark.driver.host", "localhost")
conf.set("spark.sql.debug.maxToStringFields", 1000)
conf.set("spark.sql.hive.metastore.version", "2.3.7")
conf.set("spark.sql.hive.metastore.schema.verification", "false")
conf.set("spark.sql.hive.metastore.jars", "builtin")
conf.set("spark.sql.hive.metastore.uris", "thrift://localhost:9083")
conf.set("spark.sql.catalogImplementation", "hive")
conf.set("spark.sql.cerespower.session.environment", "local")
spark.stop()
con = SparkContext(conf=conf)
sess = SparkSession(con)
builder = sess.builder.config(conf=conf)
return configure_spark_with_delta_pip(builder).getOrCreate()
@staticmethod
def is_databricks_connect():
"""
Determines whether the spark session is using databricks-connect, based on the existence of a 'databricks'
directory within the SPARK_HOME directory
:param spark: the spark session
:return: True if using databricks-connect to connect to a cluster, else False
"""
return Path(os.environ.get('SPARK_HOME'), 'databricks').exists()
@staticmethod
def is_cluster_direct_exec(spark):
"""
Determines whether executing directly on cluster, based on the existence of the clusterName configuration
setting
:param spark: the spark session
:return: True if executing directly on a cluster, else False
"""
# Note: using spark.conf.get(...) will cause the cluster to start, whereas spark.sparkContext.getConf().get does
# not. As we may want to change the clusterid when using databricks-connect we don't want to start the wrong
# cluster prematurely.
return spark.sparkContext.getConf().get("spark.databricks.clusterUsageTags.clusterName", None) is not None
Note this has been updated to use the Delta OSS 1.0 library, with the handy configure_spark_with_delta_pip function.
We can test our local hive metastore is working simply by creating some objects to store therein and confirming that these are persisted across SparkSession lifetimes.
import ntpath
import posixpath
from os import path
from SparkSessionUtil import SparkSessionUtil
data_root = 'd:\dev\data'
db_name = 'test_metastore_persist'
table_name = 'test_table'
db_path = f"'{path.join(data_root, db_name)}'".replace(ntpath.sep, posixpath.sep)
spark = SparkSessionUtil.get_configured_spark_session()
spark.sql(f"""create database if not exists {db_name} location {db_path}""")
spark.sql(f"""create table if not exists {db_name}.{table_name}(Id int not null)""")
# reset our spark session
spark = None
spark = SparkSessionUtil.get_configured_spark_session()
# confirm the database and table created above are available in the metastore
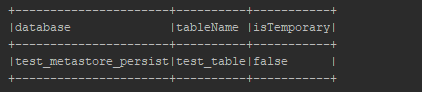
spark.sql(f"show tables in {db_name}").show(truncate=False)
After recreating the spark session, we see that we still have our database and table previously created. Success!
The Story So Far…
Along time ago in a gala…. no wait, stop, back up, more, more, right, thanks, that’s already been done. Right, where were we? Ah yes, so a quick summary of where we’re at with our local Spark setup and what we’ve covered off to date within this series:
- IDE integration – we’re really cooking with our code completion, support for testing frameworks, debugging, refactoring, blah de blah blah – the list goes on but you get the point. Using an IDE is hands down the way to go for the best development productivity. And productive developers are happier developers, well generally speaking anyway.
- Delta OSS functionality – bridging the gap between the data lake and data warehouse worlds. Sounds good to me.
- Our very own local hive metastore – ah bless, isn’t it cute? Even when it burps up a bit of metadata on your shoulder. Work in isolation, leverage the metadata within your code, put on your favourite Harry Belafonte album and smile.
- Work locally, unit test locally, don’t get things thrown at you for breaking shared environments. Sneer at those who don’t have the firepower of this fully armed and operational battle sta… oh no sorry, it happened again, I know, I know, I’m working on it. Okay maybe no sneering but at least feel free to be a bit smug about your databricks development endeavours.
Right so with all that said, in our next post we’ll get round to looking at some approaches to testing our code for successful Databricks deliveries.
Nigel Meakins administrator
Having worked for many years in the world of data and analytics, I enjoy following new innovations and understanding how best to apply them within business. I have a broad technical skill set and an acute awareness of how to make Agile work on data projects. Working at all levels and in a variety of roles on projects, I help our clients understand how the latest technology can be applied to realise greater value from their data.







About the author