Partition Elimination with Power BI – Part 3, Integers
In part 1 and part 2 of this series we looked at how the SQL generated by Power BI in combination with the data type of the partition key in the source data can impact the likelihood of partition elimination taking place. We also discussed how the SQL statements generated by M & DAX convert date/datetime data types:
- DAX converts any flavour of date/datetime to a SQL datetime data type.
- Power Query converts any flavour of date/datetime to a SQL datetime2 data type.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |
Working with Integers
A fairly common way to implement dates/date partitioning on large fact tables in a data warehouse is to use integer fields for the partition key (e.g. 20191231). The good news is that both M and DAX will pass a predicate on the partition key through to SQL with no fundamental change to the data type i.e. partition elimination takes place as expected, joy!
The example below uses a simple measure against a DirectQuery data source, partitioned on an integer field.
Table Definition
create table dbo.MonthlyStuffInt ( MonthDateKey int not null, TotalAmount decimal(10, 5) not null, index ccix_MonthlyStuffInt clustered columnstore) on psMonthlyInt(MonthDateKey);
Power BI
In Power BI I have a slicer on the MonthDateKey column and a measure displayed in a card visual that sums TotalAmount.
Total Amount = SUM ( MonthlyStuff[TotalAmount] )

SQL Generated by Power BI
Using DAX Studio or Azure Data Studio to trace the above, I can capture the following SQL generated by the DAX expression:
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = 20160501
)
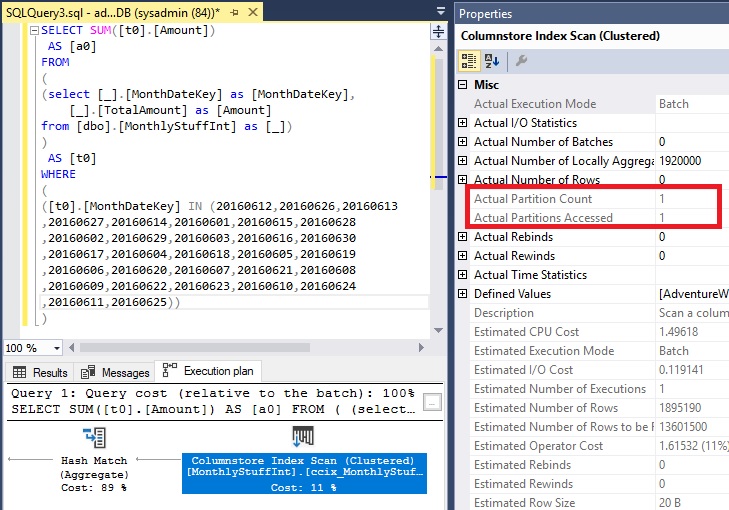
Execution Plan
If I execute the query in SSMS, I can see that partition elimination takes place.

That all looks good, right?
It does indeed but we’d generally use a date dimension table to improve the browsability of the data model and when doing so, we could lose the partition elimination functionality we see above.
In the below example I have set up a date dimension table, related to a fact table, both using DirectQuery as the storage mode. To improve the browsability of the data model I’ve used the MonthYear field from the date dimension in the slicer, something I suspect is much more representative of the real world.
Table Definition
create table
dbo.DimDate (
DateKey int not null primary key clustered
,Date date not null
,MonthYear nchar(8) not null
)
Power BI
Relationships

Visuals

SQL Generated by Power BI
SELECT SUM([t0].[Amount])
AS [a0]
FROM
((select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_]) AS [t0]
inner join
(select [$Table].[DateKey] as [DateKey],
[$Table].[Date] as [Date],
[$Table].[MonthYear] as [MonthYear]
from [dbo].[DimDate] as [$Table]) AS [t1] on
(
[t0].[MonthDateKey] = [t1].[DateKey]
)
)
WHERE
(
[t1].[MonthYear] = N'Jun-2016'
)
Unfortunately, the generated SQL statement does not use partition elimination when querying the large fact table.
Workaround
One way to invoke partition elimination and improve the query performance of the underlying SQL is to introduce a cross-island relationship between the dimension table and the fact table in Power BI.

Put simply, by introducing the cross-island relationship Power BI will bypass the join to the Date dimension table in the underlying SQL and instead, the value/s of the relationship field (DimDate[DateKey]) will be passed directly to the fact table as part of the generated DirectQuery SQL.
SQL Generated by Power BI
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
([t0].[MonthDateKey] IN (20160612,20160626,20160613
,20160627,20160614,20160601,20160615,20160628
,20160602,20160629,20160603,20160616,20160630
,20160617,20160604,20160618,20160605,20160619
,20160606,20160620,20160607,20160621,20160608
,20160609,20160622,20160623,20160610,20160624
,20160611,20160625))
)
A somewhat controversial recommendation as it’s in direct conflict with the Power BI documentation for filter propagation performance. My experience, especially in the context of large partitioned fact tables, is that the improvement you see in the data retrieval times from large fact tables (as a direct result of the ‘fact table only’ SQL statement and subsequent partition elimination) far outweighs any additional work required elsewhere.
To introduce this relationship type, change the storage mode of the date dimension table to Import.

Before:
Intra-Island Relationship (Date Dimension using DirectQuery, Fact using DirectQuery)

Profiled Query
SELECT SUM([t0].[Amount])
AS [a0]
FROM
((select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_]) AS [t0]
inner join
(select [$Table].[DateKey] as [DateKey],
[$Table].[Date] as [Date],
[$Table].[MonthYear] as [MonthYear]
from [dbo].[DimDate] as [$Table]) AS [t1] on
(
[t0].[MonthDateKey] = [t1].[DateKey]
)
)
WHERE
(
[t1].[MonthYear] = N'Jun-2016'
)
Partition Elimination does not take place

After:
Cross-Island Relationship (Date Dimension using Import Storage Mode, Fact using DirectQuery)
Profiled Query
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
([t0].[MonthDateKey] IN (20160612,20160626,20160613
,20160627,20160614,20160601,20160615,20160628
,20160602,20160629,20160603,20160616,20160630
,20160617,20160604,20160618,20160605,20160619
,20160606,20160620,20160607,20160621,20160608
,20160609,20160622,20160623,20160610,20160624
,20160611,20160625))
)
Partition Elimination takes place and we see a reduction in CPU and reads. The simplified query plan also came with the added benefit of aggregate pushdown on the columnstore index which would contribute to the improvement in performance.
Conclusion
If you are using a dimension table to improve the browsability of the data model, and you want to harness partition elimination to improve query performance in DirectQuery against very large fact tables then consider introducing a cross-island relationship between the dimension table and the fact table. This can be achieved by setting the dimension table to use Import mode. Familiarise yourself with the limitations before doing so and as always, profile your queries to ensure you’re obtaining optimal performance from your solution because one size never fits all.
Partition Elimination with Power BI – Part 2, Dates & DateTimes
In part 1 of this series we looked at how the SQL generated by Power BI, in combination with the data type of your partitioned columns in the source data, can impact the likelihood of partition elimination taking place. We also discussed how the SQL statements generated by M & DAX convert date/datetime data types:
- DAX converts any flavour of date/datetime to a SQL datetime data type.
- Power Query converts any flavour of date/datetime to a SQL datetime2 data type.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |
In this post, I’ll dig a little further into the detail and demonstrate the issue at hand with the use of some code snippets when working with a date column.
Setup
I have a SQL table shoved with some test data that I’ve partitioned by date (monthly) as follows:
create partition function pfMonthly (date) as range right for values( '20190101','20190201' ,'20190301','20190401' ,'20190501','20190601' );
create partition scheme psMonthly as partition pfMonthly all to ([PRIMARY]);
create table dbo.MonthlyStuff ( MonthDateKey date not null , TotalAmount decimal(10, 5) not null , index ccix_MonthlyStuff clustered columnstore ) on psMonthly(MonthDateKey);
Power Query (M) –
Using the import storage mode, the following Power Query statement is used to filter a monthly slice of the data in Power BI.
let
Source = Sql.Databases("mydbserver.database.windows.net"),
mydb= Source{[Name="mydb"]}[Data],
dbo_MonthlyStuff = mydb{[Schema="dbo",Item="MonthlyStuff"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_MonthlyStuff
, each ([MonthDateKey] = #date(2019, 2, 1)))
in
#"Filtered Rows"
Query folding takes place, producing the following native query (below). Note the correct data type (date) has been detected by Power Query however the native SQL query converts the filter to a datetime2:

Power Query Native Query – datetime2 Conversion
If I plug the generated SQL into SQL Server Management Studio and view the execution plan I can see that partition elimination does not take place against my partitioned table.
select [_].[MonthDateKey] , [_].[TotalAmount] from [dbo].[MonthlyStuff] as [_] where [_].[MonthDateKey] = convert(datetime2, '2019-02-01 00:00:00')

This is due to the misalignment of the data type in the predicate of the SQL statement (generated by M) with that of the data type of the partition key in the database. The source partition key is using the SQL date datatype and the SQL generated by M is casting the field to a datetime2.
To demonstrate this further, if I change the query manually in SSMS to use date conversion, partition elimination takes place resulting in much lower CPU and I/O overhead.
select [_].[MonthDateKey] , [_].[TotalAmount] from [dbo].[MonthlyStuff] as [_] where [_].[MonthDateKey] = convert(date, '2019-02-01 00:00:00')

Profiler Statistics without Partition Elimination
CPU: 4250000 Reads: 45684
Profiler Statistics with Partition Elimination
CPU: 578000 Reads: 4274
DAX
Now let’s demonstrate the issue using DAX with DirectQuery. If I use DirectQuery storage mode in Power BI and run a calculation against the underlying partitioned table, filtered to a particular month, I see a similar issue.
In Power BI I have a slicer on the MonthDateKey column (set as a date datatype) and a measure, that sums TotalAmount, displayed in a card visual.

Total Amount = SUM ( MonthlyStuff[TotalAmount] )
The following SQL is generated by the DAX expression when using DAX Studio or Azure Data Studio to trace the above.
SELECT SUM([t0].[TotalAmount])
AS [a0]
FROM
(
(select [$Table].[MonthDateKey] as [MonthDateKey],
[$Table].[TotalAmount] as [TotalAmount]
from [dbo].[MonthlyStuff] as [$Table])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = CAST( '20190201 00:00:00' AS datetime)
)
As you can see from the below, once again we fail to harness the power of partition elimination. This is due to the misalignment of the data type in the predicate of the SQL statement (generated by DAX) and the data type of the source column. Partition elimination does not take place because the source column is using the SQL date datatype and the SQL generated by DAX is casting to a datetime data type.

To demonstrate this further, if I change the query manually in SSMS to use date conversion, partition elimination takes place and results in much lower CPU and I/O overhead.
SELECT SUM([t0].[TotalAmount])
AS [a0]
FROM
(
(select [$Table].[MonthDateKey] as [MonthDateKey],
[$Table].[TotalAmount] as [TotalAmount]
from [dbo].[MonthlyStuff] as [$Table])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = CAST( '20190201 00:00:00' AS date)
)

Profiler Statistics without Partition Elimination
CPU: 1640000 Reads: 27681
Profiler Statistics with Partition Elimination
CPU: 266000 Reads: 4274
Conclusion
If you want to harness partition elimination to improve query performance in DirectQuery mode and reduce load times in Import mode, then it’s worth keeping in mind how DAX and M convert the various date/datetime data types in the underlying SQL. As always, profile your queries and ensure they are performant before you commit.
In part 3 of this series we’ll look at partitioned tables that use an integer as the date partition key, a common practice in data warehousing.
Partition Elimination with Power BI – Part 1, Overview
This series will focus on the use of partition elimination when using Power BI to query partitioned tables in a Microsoft SQL Database (On-Prem or Azure).
Partition elimination can significantly improve Power BI DirectQuery performance. Similarly, Power BI Import models that target specific partition slices across very large datasets can see a reduction in load duration by using partition elimination. Unsurprisingly, as with all things tech, there are a few gotchas to look out for along the way. With partition elimination, the big gotcha is sensitivity to data type alignment between the predicate of the SQL query and the partition key of the partitioned table.
In this post, you’ll find an overview of the data type alignment issues we’re facing. Part 2 will cover some code examples and query plans to demonstrate the problem in more detail. My final write-up of the series will take a closer look at Power BI DirectQuery against tables partitioned on an integer datekey, a common practice in data warehousing.
Before we start, let’s briefly run through some terminology for those less familiar with table partitioning.
Table Partitioning
I won’t go into the details on this but in short, it’s a way of splitting large tables into smaller chunks which the SQL optimiser can (if it so chooses) access very quickly using a technique called partition elimination.
Check out the official Microsoft documentation for full details, and peruse this excellent post written by Cathrine Wilhemsen for a great introduction to the topic.
Partition Elimination
Copping out once again, I won’t be going into the details. In essence, if you write a query against your partitioned table which includes a filter on the partition key then partition elimination can take place, provided the optimiser deems it so :-). This detailed post by Kendra Little discusses the query performance we’re aiming to achieve via the dynamic SQL generated by Power BI.
What’s in a Data Type?
….well, everything. As powerful as partition elimination can be, it’s a sensitive beast. You need to make sure the data types used in your query align exactly with the data type of your partition key in your database. An example of this sensitivity is covered in this great post by Kendra Little.
No big deal, right? Provided you have control over the SQL syntax then it’s no big deal. However, with Power BI we’re at the mercy of the application and the SQL that Power BI generates via DAX & M.
DAX & M SQL Generation in Power BI
The SQL generated by a DAX expression against a DirectQuery datasource will cast dates and datetimes as a SQL datetime datatype e.g. cast('20190909' as datetime). The SQL generated by a M expression will cast dates and datetimes as a SQL datetime2 data type with default precision e.g. cast('20190909' as datetime2).
What’s the impact of this? Well, for example, if you’re running DirectQuery against large fact tables that are partitioned on a date data type and your Power BI Analysis includes a date filter on the partition key, partition elimination will not take place as the underlying dynamic SQL from Power BI will cast your date filter into a datetime or datetime2 data type, depending on the expression language used i.e. DAX or M.
The below table provides a summary of where partition elimination will and won’t take place.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |
Dynamically Flatten a Parent-Child Hierarchy using Power Query M
Introduction
For those of you familiar with recursive common table expressions in SQL, iterating through a parent-child hierarchy of data is a fairly straight forward process. There are several examples available which demonstrate how one could approach this problem in Power Query M. In this post, we’ll use recursion and dynamic field retrieval to loop through and dynamically flatten a parent-child hierarchy using Power Query M.
Show and Tell
Before we begin, let’s take a quick look at an example of the function being invoked in Power BI. This should hopefully give you some idea of where we’re heading with this.

Dynamically Flatten a Parent-Child Hierarchy using Power Query M
Sample Data
Let’s look at some sample data to get a feel for the type of data the function requires as input and the resultant dataset the function will output.
Input
| ParentNodeID | ParentNodeName | ChildNodeID | ChildNodeName |
|---|---|---|---|
| 100 | Stringer | 2 | Shamrock |
| 200 | Avon | 201 | Levy |
| 200 | Avon | 202 | Brianna |
| 200 | Avon | 203 | Wee-Bey |
| 2 | Shamrock | 3 | Slim Charles |
| 3 | Slim Charles | 51 | Bodie |
| 3 | Slim Charles | 52 | Poot |
| 3 | Slim Charles | 53 | Bernard |
| 51 | Bodie | 61 | Sterling |
| 51 | Bodie | 62 | Pudding |
| 52 | Poot | 61 | Sterling |
| 52 | Poot | 62 | Pudding |
Output
| ParentNodeID | ChildNodeID1 | ChildNodeID2 | ChildNodeID3 | ChildNodeID4 | ParentNodeName | ChildNodeName1 | ChildNodeName2 | ChildNodeName3 | ChildNodeName4 | HierarchyLevel | HierarchyPath | IsLeafLevel | HierarchyNodeID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | Stringer | 1 | 100 | false | 100 | ||||||||
| 100 | 2 | Stringer | Shamrock | 2 | 100|2 | false | 2 | ||||||
| 100 | 2 | 3 | Stringer | Shamrock | Slim Charles | 3 | 100|2|3 | false | 3 | ||||
| 100 | 2 | 3 | 51 | Stringer | Shamrock | Slim Charles | Bodie | 4 | 100|2|3|51 | false | 51 | ||
| 100 | 2 | 3 | 51 | 61 | Stringer | Shamrock | Slim Charles | Bodie | Sterling | 5 | 100|2|3|51|61 | true | 61 |
| 100 | 2 | 3 | 51 | 62 | Stringer | Shamrock | Slim Charles | Bodie | Pudding | 5 | 100|2|3|51|62 | true | 62 |
| 100 | 2 | 3 | 52 | Stringer | Shamrock | Slim Charles | Poot | 4 | 100|2|3|52 | false | 52 | ||
| 100 | 2 | 3 | 52 | 61 | Stringer | Shamrock | Slim Charles | Poot | Sterling | 5 | 100|2|3|52|61 | true | 61 |
| 100 | 2 | 3 | 52 | 62 | Stringer | Shamrock | Slim Charles | Poot | Pudding | 5 | 100|2|3|52|62 | true | 62 |
| 100 | 2 | 3 | 53 | Stringer | Shamrock | Slim Charles | Bernard | 4 | 100|2|3|53 | true | 53 | ||
| 200 | Avon | 1 | 200 | false | 200 | ||||||||
| 200 | 202 | Avon | Brianna | 2 | 200|202 | true | 202 | ||||||
| 200 | 201 | Avon | Levy | 2 | 200|201 | true | 201 | ||||||
| 200 | 203 | Avon | Wee-Bey | 2 | 200|203 | true | 203 |
Power Query M Function
The fFlattenHiearchy function consists of an outer function and a recursive inner function.
The outer function will:
- Identify the top level parents
- Trigger the flattening
- Bolt on a few metadata columns
The inner function will:
- Self join onto the input hierarchy table to identify the next level of children within the hierarchy
- Filter out rows where the parent = child, to avoid infinite recursion
Flatten the hierarchy
The below code is used to build the basic hierarchy structure:
(
hierarchyTable as table
,parentKeyColumnIdentifier as text
,parentNameColumnIdentifier as text
,childKeyColumnIdentifier as text
,childNameColumnIdentifier as text
) as table =>
let
#"Get Root Parents" = Table.Distinct(
Table.SelectColumns(
Table.NestedJoin(hierarchyTable
,parentKeyColumnIdentifier
,hierarchyTable
,childKeyColumnIdentifier
,"ROOT.PARENTS"
,JoinKind.LeftAnti
)
,{
parentKeyColumnIdentifier
,parentNameColumnIdentifier
}
)
),
#"Generate Hierarchy" = fGetNextHierarchyLevel(
#"Get Root Parents"
,parentKeyColumnIdentifier
,1
),
fGetNextHierarchyLevel = (
parentsTable as table
,nextParentKeyColumnIdentifier as text
,hierarchyLevel as number
) =>
let
vNextParentKey = childKeyColumnIdentifier & Text.From(hierarchyLevel),
vNextParentName = childNameColumnIdentifier & Text.From(hierarchyLevel),
#"Left Join - hierarchyTable (Get Children)" = Table.NestedJoin(parentsTable
,nextParentKeyColumnIdentifier
,hierarchyTable
,parentKeyColumnIdentifier
,"NODE.CHILDREN"
,JoinKind.LeftOuter
),
#"Expand Column - NODE.CHILDREN" = Table.ExpandTableColumn(#"Left Join - hierarchyTable (Get Children)"
,"NODE.CHILDREN"
,{
childKeyColumnIdentifier
,childNameColumnIdentifier
},{
vNextParentKey
,vNextParentName
}
),
#"Filter Rows - Parents with Children" = Table.SelectRows(#"Expand Column - NODE.CHILDREN"
,each Record.Field(_,vNextParentKey) <> null
and Record.Field(_,vNextParentKey) <> Record.Field(_,nextParentKeyColumnIdentifier)
),
#"Generate Next Hierarchy Level" = if Table.IsEmpty(#"Filter Rows - Parents with Children")
then parentsTable
else Table.Combine(
{
parentsTable
,@fGetNextHierarchyLevel(
#"Filter Rows - Parents with Children"
,vNextParentKey
,hierarchyLevel + 1
)
}
)
in
#"Generate Next Hierarchy Level"
in
#"Generate Hierarchy"
Add additional metadata
Additional metadata columns can be added to the hierarchy by using the code below. My original approach was to update these columns in each iteration of the hierarchy and although the code was slightly more digestible in comparison to the below, I did find it came at the expense of performance.
#"Add Column - HierarchyPath" = Table.AddColumn(#"Generate Hierarchy",
"HierarchyPath"
,each Text.Combine(
List.Transform(
Record.FieldValues(
Record.SelectFields(_,
List.Select(Table.ColumnNames(#"Generate Hierarchy")
,each Text.StartsWith(_,childKeyColumnIdentifier)
or Text.StartsWith(_,parentKeyColumnIdentifier)
)
)
)
,each Text.From(_)
)
,"|"
)
,type text
),
#"Add Column - HierarchyNodeID" = Table.AddColumn(#"Add Column - HierarchyPath",
"HierarchyNodeID"
,each List.Last(Text.Split([HierarchyPath],"|"))
,type text
),
#"Add Column - HierarchyLevel" = Table.AddColumn(#"Add Column - HierarchyNodeID",
"HierarchyLevel"
,each List.Count(Text.Split([HierarchyPath],"|"))
,Int64.Type
),
#"Add Column - IsLeafLevel" = Table.AddColumn(#"Add Column - HierarchyLevel",
"IsLeafLevel"
,each List.Contains(
List.Transform(
Table.Column(
Table.NestedJoin(hierarchyTable
,childKeyColumnIdentifier
,hierarchyTable
,parentKeyColumnIdentifier
,"LEAFLEVEL.CHILDREN"
,JoinKind.LeftAnti
)
,childKeyColumnIdentifier
)
,each Text.From(_)
)
,List.Last(Text.Split([HierarchyPath],"|"))
)
,type logical
)
The whole caboodle
Below you will find the full code for the function along with some documentation towards the end. You can plug the below code straight into a blank query in Power BI and reference it from your hierarchy query to flatten it.
let
fFlattenHierarchy = (
hierarchyTable as table
,parentKeyColumnIdentifier as text
,parentNameColumnIdentifier as text
,childKeyColumnIdentifier as text
,childNameColumnIdentifier as text
) as table =>
let
#"Get Root Parents" = Table.Distinct(
Table.SelectColumns(
Table.NestedJoin(hierarchyTable
,parentKeyColumnIdentifier
,hierarchyTable
,childKeyColumnIdentifier
,"ROOT.PARENTS"
,JoinKind.LeftAnti
)
,{
parentKeyColumnIdentifier
,parentNameColumnIdentifier
}
)
),
#"Generate Hierarchy" = fGetNextHierarchyLevel(
#"Get Root Parents"
,parentKeyColumnIdentifier
,1
),
fGetNextHierarchyLevel = (
parentsTable as table
,nextParentKeyColumnIdentifier as text
,hierarchyLevel as number
) =>
let
vNextParentKey = childKeyColumnIdentifier & Text.From(hierarchyLevel),
vNextParentName = childNameColumnIdentifier & Text.From(hierarchyLevel),
#"Left Join - hierarchyTable (Get Children)" = Table.NestedJoin(parentsTable
,nextParentKeyColumnIdentifier
,hierarchyTable
,parentKeyColumnIdentifier
,"NODE.CHILDREN"
,JoinKind.LeftOuter
),
#"Expand Column - NODE.CHILDREN" = Table.ExpandTableColumn(#"Left Join - hierarchyTable (Get Children)"
,"NODE.CHILDREN"
,{
childKeyColumnIdentifier
,childNameColumnIdentifier
},{
vNextParentKey
,vNextParentName
}
),
#"Filter Rows - Parents with Children" = Table.SelectRows(#"Expand Column - NODE.CHILDREN"
,each Record.Field(_,vNextParentKey) <> null
and Record.Field(_,vNextParentKey) <> Record.Field(_,nextParentKeyColumnIdentifier)
),
#"Generate Next Hierarchy Level" = if Table.IsEmpty(#"Filter Rows - Parents with Children")
then parentsTable
else Table.Combine(
{
parentsTable
,@fGetNextHierarchyLevel(
#"Filter Rows - Parents with Children"
,vNextParentKey
,hierarchyLevel + 1
)
}
)
in
#"Generate Next Hierarchy Level",
#"Add Column - HierarchyPath" = Table.AddColumn(#"Generate Hierarchy",
"HierarchyPath"
,each Text.Combine(
List.Transform(
Record.FieldValues(
Record.SelectFields(_,
List.Select(Table.ColumnNames(#"Generate Hierarchy")
,each Text.StartsWith(_,childKeyColumnIdentifier)
or Text.StartsWith(_,parentKeyColumnIdentifier)
)
)
)
,each Text.From(_)
)
,"|"
)
,type text
),
#"Add Column - HierarchyNodeID" = Table.AddColumn(#"Add Column - HierarchyPath",
"HierarchyNodeID"
,each List.Last(Text.Split([HierarchyPath],"|"))
,type text
),
#"Add Column - HierarchyLevel" = Table.AddColumn(#"Add Column - HierarchyNodeID",
"HierarchyLevel"
,each List.Count(Text.Split([HierarchyPath],"|"))
,Int64.Type
),
#"Add Column - IsLeafLevel" = Table.AddColumn(#"Add Column - HierarchyLevel",
"IsLeafLevel"
,each List.Contains(
List.Transform(
Table.Column(
Table.NestedJoin(hierarchyTable
,childKeyColumnIdentifier
,hierarchyTable
,parentKeyColumnIdentifier
,"LEAFLEVEL.CHILDREN"
,JoinKind.LeftAnti
)
,childKeyColumnIdentifier
)
,each Text.From(_)
)
,List.Last(Text.Split([HierarchyPath],"|"))
)
,type logical
)
in
#"Add Column - IsLeafLevel",
//Documentation
fFlattenHierarchyType = type function (
hierarchyTable as (type table meta [
Documentation.FieldCaption = "Hierarchy"
,Documentation.LongDescription = "A table containing a parent-child hierarchy"
]
)
,parentKeyColumnIdentifier as (type text meta [
Documentation.FieldCaption = "Parent Key Column Identifier"
,Documentation.LongDescription = "The name of the column used to identify the key of the parent node in the hierarchy"
,Documentation.SampleValues = { "ParentID" }
]
)
,parentNameColumnIdentifier as (type text meta [
Documentation.FieldCaption = "Parent Name Column Identifier"
,Documentation.LongDescription = "The name of the column used to identify the name of the parent node in the hierarchy"
,Documentation.SampleValues = { "ParentName" }
]
)
,childKeyColumnIdentifier as (type text meta [
Documentation.FieldCaption = "Child Key Column Identifier"
,Documentation.LongDescription = "The name of the column used to identify the key of the child node in the hierarchy"
,Documentation.SampleValues = { "ChildID" }
]
)
,childNameColumnIdentifier as (type text meta [
Documentation.FieldCaption = "Child Name Column Identifier"
,Documentation.LongDescription = "The name of the column used to identify the name of the child node in the hierarchy"
,Documentation.SampleValues = { "ChildName" }
]
)
) as list meta [
Documentation.Name = "fFlattenHierarchy"
,Documentation.LongDescription = "Returns a flattened hierarchy table from a parent-child hierarchy table input."
& "The number of columns returned is based on the depth of the hierarchy. Each child node will be prefixed"
& "with the value specified for the childNameColumnIdentifier parameter"
,Documentation.Examples = {
[
Description = "Returns a flattened hierarchy table from a parent-child hierarchy table"
,Code = "fFlattenHierarchy(barksdaleOrganisation, ""ParentNodeID"", ""ParentNodeName"", ""ChildNodeID"", ""ChildNodeName"")"
,Result = "{100,2,3,51,62,""Stringer"",""Shamrock"",""Slim Charles"",""Bodie"",""Pudding"",5,""100|2|3|51|62"",TRUE,62}"
& ",{100,2,3,51,""Stringer"",""Shamrock"",""Slim Charles"",""Bodie"",4,""100|2|3|51"",FALSE,51}"
]
}
]
in
Value.ReplaceType(fFlattenHierarchy, fFlattenHierarchyType)
Final Thoughts
It looks fairly verbose but in reality, it’s just 10 steps to flatten a hierarchy and bolt on the metadata columns, you could probably blame my code formatting for thinking otherwise. Anyone who is used to seeing common table expressions in SQL will hopefully find the logic defined in the function familiar.
In terms of performance, I’ve not pitted this against other methods nor done any performance testing but I’ve executed it against a ragged hierarchy with 11 levels spanning several thousand rows and it spat out results fairly instantaneously.
Automate Your Power BI Dataset Refresh with Python
Introduction
Most people using Power BI normally do so with Microsoft technology at the core of their business and IT operations. Power BI is rapidly adding connectors for non-Microsoft technologies and new capabilities on a monthly basis. The combination of new sources, excellent visualisation and modelling, and a low price point is leading to it being used with technologies other than the Microsoft data platform.
This blog is the result of one such project. I am currently using Power BI as the main reporting tool on a Google Cloud Platform (GCP) data project. There are lots of interesting topics to discuss given the technologies being used. However, this post is going to focus on the programmatic refreshing of your Power BI datasets using Python. “Why Python?” I hear you say. Well the workflow tool used on GCP is none other than Apache Airflow, implemented as Composer. Apache Airflow is written in Python and you create all of your workflows using Python.
When I looked at the Power BI REST API documentation all of the examples were in C#. After a lot of reading and experimenting (aka hitting my head against my desk), I had the process running the way I wanted. This post is my attempt at creating the document I wish existed when I started.
The main steps
It is important to understand the main steps involved in this process before we get into the detail. Having this high-level process clearly defined was one of the things missing from the information online.
- The first step is to create an App registration for your application. This will provide you with a client id for your app which is needed for authentication later on.
- Next you will grant your App the permissions it requested in Azure AD.
- Using the information from the previous steps you acquire an authentication token from Azure AD in your python code.
- Finally, you use the authentication token to call the Power BI REST API.
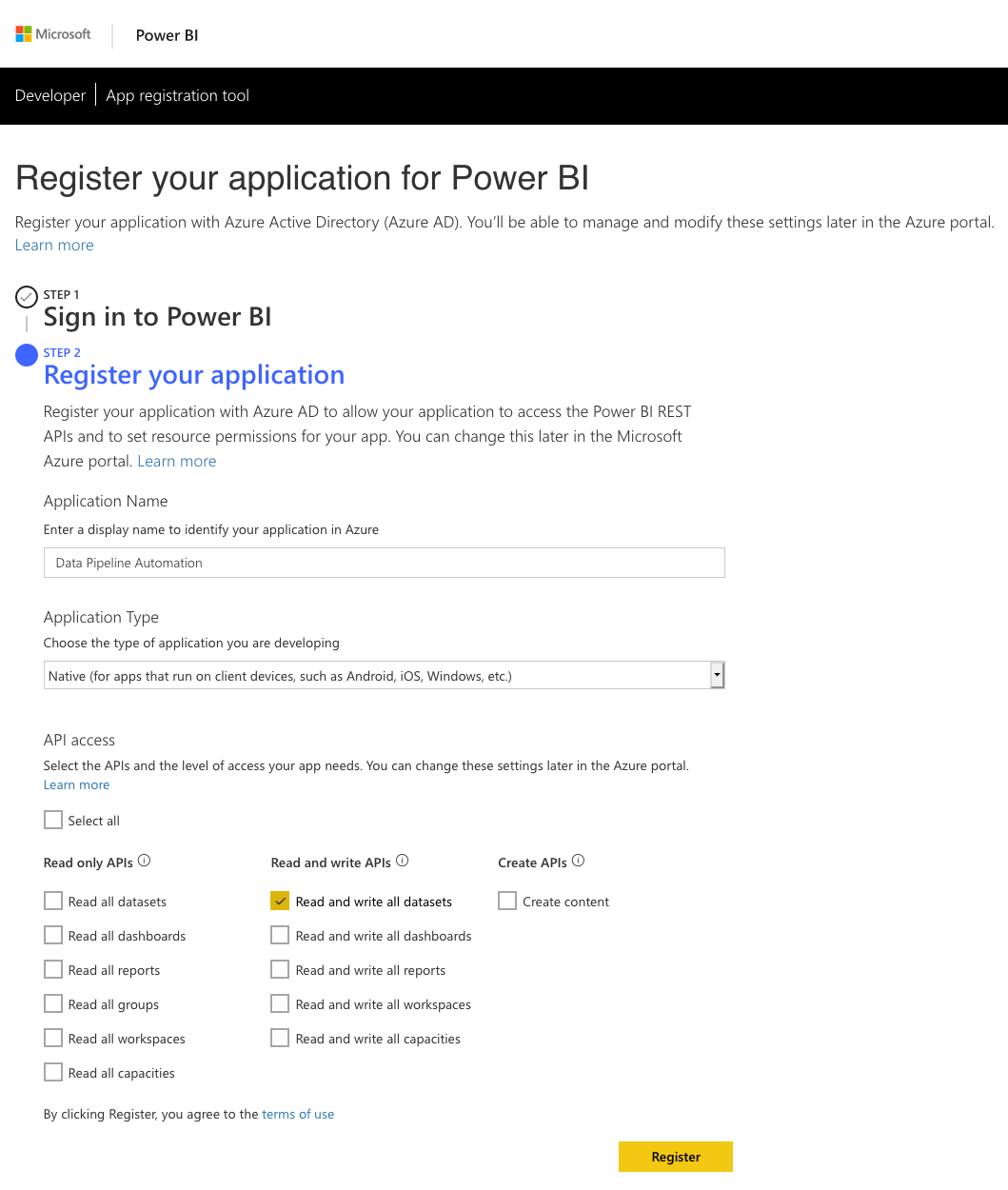
Registering your App
The first and most important part of this entire process is to create a Power BI app registration. There are multiple ways of doing this and this video from Guy in a Cube will give you all of the information you need. No matter how you choose to do your app registration there are three main things you need to know.
1. The Power BI REST API only supports delegated permissions. That means that you need to run any calls to the REST API in the context of a user. For unattended applications, such as our data pipeline step, you need to register your app as a Native app. You only receive the client id when you register it as native app. Server-side Web apps receive both a client id and client secret but this is the wrong type of app for our use case. When you authenticate from your code you will need the client id together with the username and the password of the account that has delegated these permissions to the app.
2. You need to ensure you select the correct permissions when registering your app. For our purposes we need access to Read and write all datasets. As always take the approach of providing the minimum permissions needed. You can always add more permissions later in the Azure Portal.
3. This brings us to the most overlooked yet important point which is granting permissions to the App in the Azure Portal. You need to log into the Azure Portal with the account that will be delegating the permissions to the app. This will be the account of which you will pass the username, password with the client id to authenticate against Azure AD. If you do not perform this step you will end up with authentication errors. (You might get an authentication token when you authorise but you won’t get the correct scope in the access token)

Python and the Power BI REST API
Interacting with the Power BI REST API requires a two-step process.
1. Acquiring an access token from Azure AD by supplying your client id, username and password
2. Calling the desired REST API using the access token received in step 1.
There is a choice in how you can perform step 1. You can choose to either use the ADAL Python library or pure REST calls to obtain the access token.
Before we continue a word of caution. In the examples provided below we have the client id, username and password entered directly in the code. This is for demonstration purposes only. I cannot stress this enough. For production solutions you would want to use the credential management best practice of your platform.
ADAL Library
The adal library for Python is the official Microsoft Azure Active Directory authentication library. It provides you with everything you need to authenticate against Azure AD using Python. Below is an example of the code you will use to authenticate and get your access token. Keep in mind that we have to pass the username and password along with the Client ID. No other way of authenticating will give us a token with the scopes we need to call the Power BI REST API successfully.
import adal
authority_url = 'https://login.windows.net/common'
resource_url = 'https://analysis.windows.net/powerbi/api'
client_id = <INSERT CLIENT ID>
username = <INSERT USERNAME>
password = <INSERT PASSWORD>
context = adal.AuthenticationContext(authority=authority_url,
validate_authority=True,
api_version=None)
token = context.acquire_token_with_username_password(resource=resource_url,
client_id=client_id,
username=username,
password=password)
access_token = token.get('accessToken')
As you can see the adal library makes it extremely easy to authenticate against Azure AD and get the token you need.
REST
An alternative to the ADAL library is normal REST API calls to obtain the token. Below is an example of the code you will use if you were using the requests library to make your REST calls.
import requests
url = 'https://login.microsoftonline.com/common/oauth2/token'
data = {
'grant_type': 'password',
'scope': 'https://api.powerbi.com',
'resource': 'https://analysis.windows.net/powerbi/api',
'client_id': <INSERT CLIENT ID>,
'username': <INSERT USERNAME>,
'password': <INSERT PASSWORD>
}
r = requests.post(url, data=data)
access_token = r.json().get('access_token')
Refreshing the Power BI Dataset
So now that we have gotten our access token, we can move onto the next step which is refreshing our dataset in Power BI. In order to do this, you will need one or two keys depending on where your dataset is located.
If your dataset is in the workspace of the account under which your app will be running, the “My Workspace” of that account, then you only need the dataset key of your dataset. If, however your dataset is located in an app workspace you will need to get both the group id and the dataset key.
You get these values from the URL in your browser when you navigate to the settings of the dataset. Here are examples for each one of the scenarios.
- Dataset in “My Workspace”: https://app.powerbi.com/groups/me/settings/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
- Dataset in a App Workspace: https://app.powerbi.com/groups/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/settings/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX

Once you have these keys you are ready to construct your API call to refresh your dataset. The Power BI REST API documentation shows the two different API calls.
- Dataset in “My Workspace” refresh URL: POST https://api.powerbi.com/v1.0/myorg/datasets/{datasetKey}/refreshes
- Dataset in App Workspace refresh URL: POST https://api.powerbi.com/v1.0/myorg/groups/{groupId}/datasets/{datasetKey}/refreshes
Below is an example of the code you would use to refresh a dataset in an App Workspace.
import adal
import requests
authority_url = 'https://login.windows.net/common'
resource_url = 'https://analysis.windows.net/powerbi/api'
client_id = <INSERT CLIENT ID>
username = <INSERT USERNAME>
password = <INSERT PASSWORD>
context = adal.AuthenticationContext(authority=authority_url,
validate_authority=True,
api_version=None)
token = context.acquire_token_with_username_password(resource=resource_url,
client_id=client_id,
username=username,
password=password)
access_token = token.get('accessToken')
refresh_url = 'https://api.powerbi.com/v1.0/myorg/groups/<INSERT GROUP ID>/datasets/<INSERT DATASET KEY>/refreshes'
header = {'Authorization': f'Bearer {access_token}'}
r = requests.post(url=refresh_url, headers=header)
r.raise_for_status()
Conclusion
As you can see it is extremely easy to refresh your datasets in Power BI using Python and the Power BI REST API. The most common mistakes people make which account for the majority of forum posts online are:
- Register their app as the wrong type, Server-side Web app, instead of the correct type which is Native app.
- Not granting the App permissions in the Azure portal using the account in which context it will be running.
- Trying to acquire the Azure AD token using client credentials, client id and client secret, instead of acquiring it with a username and password.
By getting the steps right you will have no problem in automating your Power BI tasks with Python or any other programming language you choose to use.



