Partition Elimination with Power BI – Part 3, Integers
In part 1 and part 2 of this series we looked at how the SQL generated by Power BI in combination with the data type of the partition key in the source data can impact the likelihood of partition elimination taking place. We also discussed how the SQL statements generated by M & DAX convert date/datetime data types:
- DAX converts any flavour of date/datetime to a SQL datetime data type.
- Power Query converts any flavour of date/datetime to a SQL datetime2 data type.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |
Working with Integers
A fairly common way to implement dates/date partitioning on large fact tables in a data warehouse is to use integer fields for the partition key (e.g. 20191231). The good news is that both M and DAX will pass a predicate on the partition key through to SQL with no fundamental change to the data type i.e. partition elimination takes place as expected, joy!
The example below uses a simple measure against a DirectQuery data source, partitioned on an integer field.
Table Definition
create table dbo.MonthlyStuffInt ( MonthDateKey int not null, TotalAmount decimal(10, 5) not null, index ccix_MonthlyStuffInt clustered columnstore) on psMonthlyInt(MonthDateKey);
Power BI
In Power BI I have a slicer on the MonthDateKey column and a measure displayed in a card visual that sums TotalAmount.
Total Amount = SUM ( MonthlyStuff[TotalAmount] )

SQL Generated by Power BI
Using DAX Studio or Azure Data Studio to trace the above, I can capture the following SQL generated by the DAX expression:
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = 20160501
)
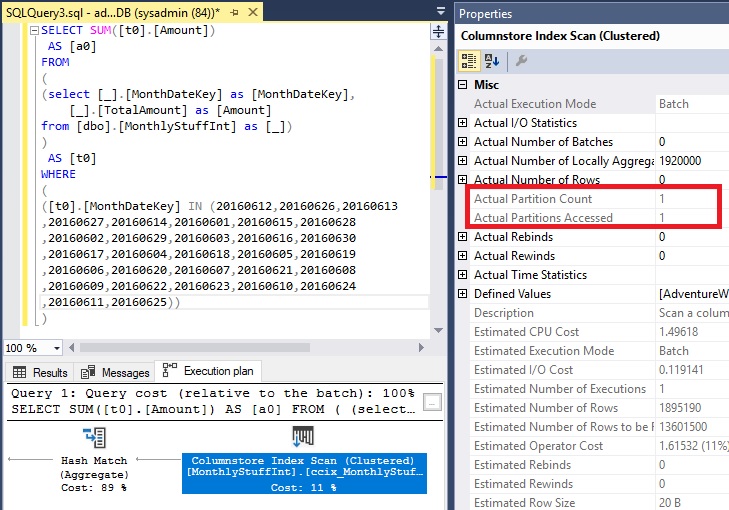
Execution Plan
If I execute the query in SSMS, I can see that partition elimination takes place.

That all looks good, right?
It does indeed but we’d generally use a date dimension table to improve the browsability of the data model and when doing so, we could lose the partition elimination functionality we see above.
In the below example I have set up a date dimension table, related to a fact table, both using DirectQuery as the storage mode. To improve the browsability of the data model I’ve used the MonthYear field from the date dimension in the slicer, something I suspect is much more representative of the real world.
Table Definition
create table
dbo.DimDate (
DateKey int not null primary key clustered
,Date date not null
,MonthYear nchar(8) not null
)
Power BI
Relationships

Visuals

SQL Generated by Power BI
SELECT SUM([t0].[Amount])
AS [a0]
FROM
((select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_]) AS [t0]
inner join
(select [$Table].[DateKey] as [DateKey],
[$Table].[Date] as [Date],
[$Table].[MonthYear] as [MonthYear]
from [dbo].[DimDate] as [$Table]) AS [t1] on
(
[t0].[MonthDateKey] = [t1].[DateKey]
)
)
WHERE
(
[t1].[MonthYear] = N'Jun-2016'
)
Unfortunately, the generated SQL statement does not use partition elimination when querying the large fact table.
Workaround
One way to invoke partition elimination and improve the query performance of the underlying SQL is to introduce a cross-island relationship between the dimension table and the fact table in Power BI.

Put simply, by introducing the cross-island relationship Power BI will bypass the join to the Date dimension table in the underlying SQL and instead, the value/s of the relationship field (DimDate[DateKey]) will be passed directly to the fact table as part of the generated DirectQuery SQL.
SQL Generated by Power BI
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
([t0].[MonthDateKey] IN (20160612,20160626,20160613
,20160627,20160614,20160601,20160615,20160628
,20160602,20160629,20160603,20160616,20160630
,20160617,20160604,20160618,20160605,20160619
,20160606,20160620,20160607,20160621,20160608
,20160609,20160622,20160623,20160610,20160624
,20160611,20160625))
)
A somewhat controversial recommendation as it’s in direct conflict with the Power BI documentation for filter propagation performance. My experience, especially in the context of large partitioned fact tables, is that the improvement you see in the data retrieval times from large fact tables (as a direct result of the ‘fact table only’ SQL statement and subsequent partition elimination) far outweighs any additional work required elsewhere.
To introduce this relationship type, change the storage mode of the date dimension table to Import.

Before:
Intra-Island Relationship (Date Dimension using DirectQuery, Fact using DirectQuery)

Profiled Query
SELECT SUM([t0].[Amount])
AS [a0]
FROM
((select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_]) AS [t0]
inner join
(select [$Table].[DateKey] as [DateKey],
[$Table].[Date] as [Date],
[$Table].[MonthYear] as [MonthYear]
from [dbo].[DimDate] as [$Table]) AS [t1] on
(
[t0].[MonthDateKey] = [t1].[DateKey]
)
)
WHERE
(
[t1].[MonthYear] = N'Jun-2016'
)
Partition Elimination does not take place

After:
Cross-Island Relationship (Date Dimension using Import Storage Mode, Fact using DirectQuery)
Profiled Query
SELECT SUM([t0].[Amount])
AS [a0]
FROM
(
(select [_].[MonthDateKey] as [MonthDateKey],
[_].[TotalAmount] as [Amount]
from [dbo].[MonthlyStuffInt] as [_])
)
AS [t0]
WHERE
(
([t0].[MonthDateKey] IN (20160612,20160626,20160613
,20160627,20160614,20160601,20160615,20160628
,20160602,20160629,20160603,20160616,20160630
,20160617,20160604,20160618,20160605,20160619
,20160606,20160620,20160607,20160621,20160608
,20160609,20160622,20160623,20160610,20160624
,20160611,20160625))
)
Partition Elimination takes place and we see a reduction in CPU and reads. The simplified query plan also came with the added benefit of aggregate pushdown on the columnstore index which would contribute to the improvement in performance.
Conclusion
If you are using a dimension table to improve the browsability of the data model, and you want to harness partition elimination to improve query performance in DirectQuery against very large fact tables then consider introducing a cross-island relationship between the dimension table and the fact table. This can be achieved by setting the dimension table to use Import mode. Familiarise yourself with the limitations before doing so and as always, profile your queries to ensure you’re obtaining optimal performance from your solution because one size never fits all.
Partition Elimination with Power BI – Part 2, Dates & DateTimes
In part 1 of this series we looked at how the SQL generated by Power BI, in combination with the data type of your partitioned columns in the source data, can impact the likelihood of partition elimination taking place. We also discussed how the SQL statements generated by M & DAX convert date/datetime data types:
- DAX converts any flavour of date/datetime to a SQL datetime data type.
- Power Query converts any flavour of date/datetime to a SQL datetime2 data type.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |
In this post, I’ll dig a little further into the detail and demonstrate the issue at hand with the use of some code snippets when working with a date column.
Setup
I have a SQL table shoved with some test data that I’ve partitioned by date (monthly) as follows:
create partition function pfMonthly (date) as range right for values( '20190101','20190201' ,'20190301','20190401' ,'20190501','20190601' );
create partition scheme psMonthly as partition pfMonthly all to ([PRIMARY]);
create table dbo.MonthlyStuff ( MonthDateKey date not null , TotalAmount decimal(10, 5) not null , index ccix_MonthlyStuff clustered columnstore ) on psMonthly(MonthDateKey);
Power Query (M) –
Using the import storage mode, the following Power Query statement is used to filter a monthly slice of the data in Power BI.
let
Source = Sql.Databases("mydbserver.database.windows.net"),
mydb= Source{[Name="mydb"]}[Data],
dbo_MonthlyStuff = mydb{[Schema="dbo",Item="MonthlyStuff"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_MonthlyStuff
, each ([MonthDateKey] = #date(2019, 2, 1)))
in
#"Filtered Rows"
Query folding takes place, producing the following native query (below). Note the correct data type (date) has been detected by Power Query however the native SQL query converts the filter to a datetime2:

Power Query Native Query – datetime2 Conversion
If I plug the generated SQL into SQL Server Management Studio and view the execution plan I can see that partition elimination does not take place against my partitioned table.
select [_].[MonthDateKey] , [_].[TotalAmount] from [dbo].[MonthlyStuff] as [_] where [_].[MonthDateKey] = convert(datetime2, '2019-02-01 00:00:00')

This is due to the misalignment of the data type in the predicate of the SQL statement (generated by M) with that of the data type of the partition key in the database. The source partition key is using the SQL date datatype and the SQL generated by M is casting the field to a datetime2.
To demonstrate this further, if I change the query manually in SSMS to use date conversion, partition elimination takes place resulting in much lower CPU and I/O overhead.
select [_].[MonthDateKey] , [_].[TotalAmount] from [dbo].[MonthlyStuff] as [_] where [_].[MonthDateKey] = convert(date, '2019-02-01 00:00:00')

Profiler Statistics without Partition Elimination
CPU: 4250000 Reads: 45684
Profiler Statistics with Partition Elimination
CPU: 578000 Reads: 4274
DAX
Now let’s demonstrate the issue using DAX with DirectQuery. If I use DirectQuery storage mode in Power BI and run a calculation against the underlying partitioned table, filtered to a particular month, I see a similar issue.
In Power BI I have a slicer on the MonthDateKey column (set as a date datatype) and a measure, that sums TotalAmount, displayed in a card visual.

Total Amount = SUM ( MonthlyStuff[TotalAmount] )
The following SQL is generated by the DAX expression when using DAX Studio or Azure Data Studio to trace the above.
SELECT SUM([t0].[TotalAmount])
AS [a0]
FROM
(
(select [$Table].[MonthDateKey] as [MonthDateKey],
[$Table].[TotalAmount] as [TotalAmount]
from [dbo].[MonthlyStuff] as [$Table])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = CAST( '20190201 00:00:00' AS datetime)
)
As you can see from the below, once again we fail to harness the power of partition elimination. This is due to the misalignment of the data type in the predicate of the SQL statement (generated by DAX) and the data type of the source column. Partition elimination does not take place because the source column is using the SQL date datatype and the SQL generated by DAX is casting to a datetime data type.

To demonstrate this further, if I change the query manually in SSMS to use date conversion, partition elimination takes place and results in much lower CPU and I/O overhead.
SELECT SUM([t0].[TotalAmount])
AS [a0]
FROM
(
(select [$Table].[MonthDateKey] as [MonthDateKey],
[$Table].[TotalAmount] as [TotalAmount]
from [dbo].[MonthlyStuff] as [$Table])
)
AS [t0]
WHERE
(
[t0].[MonthDateKey] = CAST( '20190201 00:00:00' AS date)
)

Profiler Statistics without Partition Elimination
CPU: 1640000 Reads: 27681
Profiler Statistics with Partition Elimination
CPU: 266000 Reads: 4274
Conclusion
If you want to harness partition elimination to improve query performance in DirectQuery mode and reduce load times in Import mode, then it’s worth keeping in mind how DAX and M convert the various date/datetime data types in the underlying SQL. As always, profile your queries and ensure they are performant before you commit.
In part 3 of this series we’ll look at partitioned tables that use an integer as the date partition key, a common practice in data warehousing.
Partition Elimination with Power BI – Part 1, Overview
This series will focus on the use of partition elimination when using Power BI to query partitioned tables in a Microsoft SQL Database (On-Prem or Azure).
Partition elimination can significantly improve Power BI DirectQuery performance. Similarly, Power BI Import models that target specific partition slices across very large datasets can see a reduction in load duration by using partition elimination. Unsurprisingly, as with all things tech, there are a few gotchas to look out for along the way. With partition elimination, the big gotcha is sensitivity to data type alignment between the predicate of the SQL query and the partition key of the partitioned table.
In this post, you’ll find an overview of the data type alignment issues we’re facing. Part 2 will cover some code examples and query plans to demonstrate the problem in more detail. My final write-up of the series will take a closer look at Power BI DirectQuery against tables partitioned on an integer datekey, a common practice in data warehousing.
Before we start, let’s briefly run through some terminology for those less familiar with table partitioning.
Table Partitioning
I won’t go into the details on this but in short, it’s a way of splitting large tables into smaller chunks which the SQL optimiser can (if it so chooses) access very quickly using a technique called partition elimination.
Check out the official Microsoft documentation for full details, and peruse this excellent post written by Cathrine Wilhemsen for a great introduction to the topic.
Partition Elimination
Copping out once again, I won’t be going into the details. In essence, if you write a query against your partitioned table which includes a filter on the partition key then partition elimination can take place, provided the optimiser deems it so :-). This detailed post by Kendra Little discusses the query performance we’re aiming to achieve via the dynamic SQL generated by Power BI.
What’s in a Data Type?
….well, everything. As powerful as partition elimination can be, it’s a sensitive beast. You need to make sure the data types used in your query align exactly with the data type of your partition key in your database. An example of this sensitivity is covered in this great post by Kendra Little.
No big deal, right? Provided you have control over the SQL syntax then it’s no big deal. However, with Power BI we’re at the mercy of the application and the SQL that Power BI generates via DAX & M.
DAX & M SQL Generation in Power BI
The SQL generated by a DAX expression against a DirectQuery datasource will cast dates and datetimes as a SQL datetime datatype e.g. cast('20190909' as datetime). The SQL generated by a M expression will cast dates and datetimes as a SQL datetime2 data type with default precision e.g. cast('20190909' as datetime2).
What’s the impact of this? Well, for example, if you’re running DirectQuery against large fact tables that are partitioned on a date data type and your Power BI Analysis includes a date filter on the partition key, partition elimination will not take place as the underlying dynamic SQL from Power BI will cast your date filter into a datetime or datetime2 data type, depending on the expression language used i.e. DAX or M.
The below table provides a summary of where partition elimination will and won’t take place.
| Partition Key Data Type | Date Filter Expression Language | Partition Elimination Possible | Expression Langauge Data Type Conversion |
|---|---|---|---|
| date | M | No | datetime2(7) |
| date | DAX | No | datetime |
| datetime | M | No | datetime2(7) |
| datetime | DAX | Yes | datetime |
| datetime2(7) | M | Yes | datetime2(7) |
| datetime2(7) | DAX | No | datetime |
| datetime2(other) | M | No | datetime2(7) |
| datetime2(other) | DAX | No | datetime |
| int | M | Yes | int |
| int | DAX | Yes | int |



