
Build Your Own WinUtils for Spark
The option of setting up a local spark environment on a Windows build, whether for developing spark applications, running CI/CD activities or whatever, brings many benefits for productivity and cost reduction. For this to happen however, you’ll need to have an executable file called winutils.exe. This post serves to supplement the main thread of the series on Development on Databricks, making a stop at C++ world (don’t panic!) as we handle the situation where you are required to build your own WinUtils executable for use with Spark. It is intended for an audience unfamiliar with building C++ projects, and as such seasoned C++ developers will no doubt want to skip some of the ‘hand-holding’ steps.
What Does Spark Need WinUtils For?
In order to run Apache Spark locally, it is required to use an element of the Hadoop code base known as ‘WinUtils’. This allows management of the POSIX file system permissions that the HDFS file system requires of the local file system. If Spark cannot find the required service executable, WinUtils.exe, it will throw a warning as below, but will proceed to try and run the Spark shell.

Spark requires that you have set POSIX compatible permissions for a temporary directory used by the Hive metastore, which defaults to C:\tmp\hive (the location of this can be changed as described here ). In order to set these POSIX permissions you need to use WinUtils, and without these permissions being set correctly any attempt to use Spark SQL to access the Hive metastore will fail. You’ll get an error complaining about lack of writable access to the above scratch directory and Spark will throw a full blown sulk like a kid deprived of their Nintendo Switch. Here’s a sulk it threw earlier…
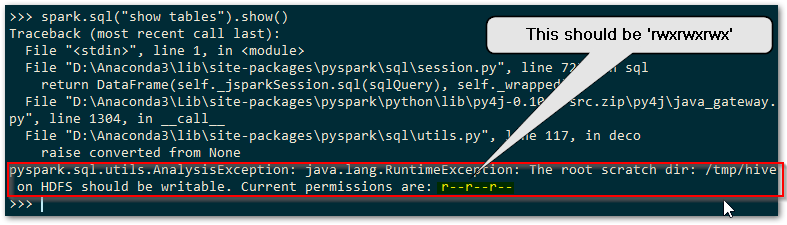
You’ll need to use WinUtils as below in order to set the POSIX permissions for HDFS that the Hive metastore will be happy with.
# set the rwxrwxrwx POSIX permissions winutils chmod -R 777 c:\tmp\hive
So if you’re on Windows and want to run Spark, WinUtils is a necessity to get going with anything involving the Hive metastore.
Why Build Your Own?
Existing Prebuilt WinUtils Repositories
There are GitHub repositories that are independently maintained, available here, with a previous one here (no longer maintained) that contains the compiled exe file and any supporting libraries, for the various versions of the Hadoop code base included within Apache Spark. If you don’t need to provide transparency of the source of the code used you can always simply grab the compiled files for local use rather than going to the trouble of compiling your own.
The maintainer of the second compiled WinUtils repo above details the process that they go to in order to ensure that the code is compiled from the legitimate source, with no routes for malware to infiltrate. This may however still not be acceptable from a security perspective. The security administrators and custodians of your systems will quite probably have tight controls on you simply copying files whose originating source code cannot be verified 100%, for obvious reasons. We all know the perils of simply downloading and running opaque executables and so the option to build your own winutils executable for Spark will be welcome.
Compiling from Source
WinUtils is included within the main Apache Spark GitHub repository, with all dependent source code available for inspection as required. As you can see from the repo, the Hadoop code base is huge, but the elements we really need are only a small fraction of this. Getting the whole Hadoop code base to build on a Windows machine is no easy task, and we won’t be trying this here. You’ll need a very specific set of dependent components and a dedicated build machine if you want to build the full Hadoop repo, which is the approach taken in the above prebuilt repos. You can find a number of tutorials on how to do this on the web, such as the one found here. Note the specific components required based on the code base. For our purposes we can focus on just the WinUtils code itself. I’ll be using the ‘branch-3.2’ branch for this exercise.
So having cloned/downloaded the Apache Hadoop repo and checked out to the ‘branch-3.2’, the desired WinUtils code can be found within our local repo at
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\winutils
and
hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native
You’ll notice that the above code is written in C/C++, and so if we’re going to build the executable we need to be able to compile C/C++ code. No great surprises there. I should probably confess at this point that I haven’t touched C++ for a good few years to any advanced degree, so I’m far removed from being a C++ developer these days and am going to simplify things here (to avoid confusing me and possibly you).
Tools for the Job
If you have Visual Studio installed you can simply extend the Features to include C++ desktop applications, thereby gaining the required compiler, linker etc. If you don’t have Visual Studio, you can still get the Build Tools as a separate download, available here for VS2019. Once you have the required tools, we can look at what is required to build your own WinUtils executable.
Building the Code
Cue trumpets… pap pap pap pap paaaaeeeerrrrr…. oh hold on, there’s still a little way to go. Trumpets, come back in a bit, grab a coffee, play some Uno or something, won’t be long, nearly there.
Desired Output
In the latest version of the WinUtils code, there are two projects in the WinUtils directory. One is for the WinUtils.exe used directly from Spark on Windows, and the other is for a library, libwinutils.lib, that will be referenced from WinUtils.exe. If you look at the precompiled repos mentioned above, for each version of Hadoop you’ll see a number of files that are output in addition to the two previously mentioned. We’ll be needing the hadoop.dll and hadoop.lib files for our purposes of running Spark on Windows. We don’t need the hdfs.*, mapred.* or yarn.* files as these components of Hadoop won’t be of interest.
We want to be able to compile both the winutils, libwinutils and native projects and make use of the resultant files. If you are not familiar with building code using Microsoft Visual Studio and associated tooling, these files will be generated in a default output location such as winutils\debug or winutils\Release, depending on the configuration chosen (more on that below). Okay, with that end goal in mind, let’s look to building the code.
Retarget Projects with Visual Studio
The projects are based on the VS2010 IDE, so you’ll get upgrade messages when opening if you are on a later version.
Assuming you are on a later Windows build than Windows 8.1, you will need to change the Build tools and Windows SDK targeted by the solution projects. The first time you open the winutils.sln or native.sln files you will be greeted with the following dialogue and should choose whatever is the latest installed on your system. For me this was v142 as I’m on Visual Studio 2019, and SDK 10.0.19041.0.
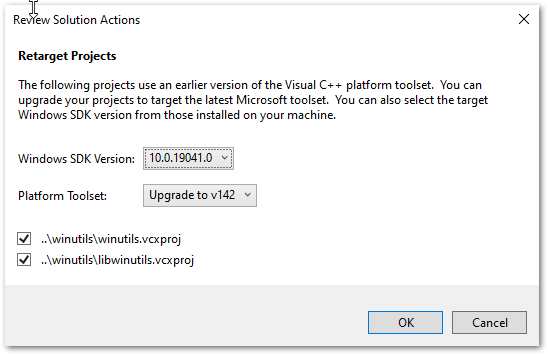
WinUtils Solution Code Amendments Required
Okay, so we’ve grabbed the code base and installed the required tools to build the code. There are a couple of things that need to be considered for a successful build of your own WinUtils for Spark.
libwinutils.c Issues?
You’ll see the following errors in the libwinutils.c source file, which imply an issue with the code.

However, the issue is actually with the lack of values for the preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE.
WSCE Preprocessor Directive Values
The preprocessor directives WSCE_CONFIG_DIR and WSCE_CONFIG_FILE can be seen defined within the winutils and libwinutils projects, as the project file excerpt below shows.

Notice that they are populated from parameters passed in to the build, as denoted by the WSCE_CONFIG_DIR=$(WsceConfigDir) syntax. So when building the winutils project it expects these values to be passed in. Right, time to find what values are used in the Hadoop code base to see the relevance of this…
Values from Maven Pom Files
In order to understand what parameters are required to be passed to the build, we need to take a look at the Maven pom file that is used to build this part of the code base, found at
\hadoop-trunk\hadoop-common-project\hadoop-common\pom.xml
Firstly, at the top of the file, we see the following properties defined:


The various parameters passed define the configuration, platform, output directories etc, and also the two expected values, WsceConfigDir, and WsceConfigFile that will feed the preprocessor directives mentioned. These are taken from the property references ${wsce.config.dir} and ${wsce.config.file} respectively. The values for these are supplied, as we’ve just seen, in the property definitions at the top of the pom file. Right, glad we cleared that one up.
For context, these values are used as part of the Yarn Secure Containers setup, which you can read about here. We’ll need to ensure that these values are passed in for each of our build methods detailed below. As we won’t actually be using the Yarn elements for our purposes of running local Spark, we don’t need to concern ourselves with the directory and file in question not being available. We can pass empty strings, “”, for each if we want, use the values from the pom file, or use other string values. I’m going to stick with the pom file values for this exercise.
The code within the hadoop-trunk\hadoop-common-project\hadoop-common\src\main\native folder that creates the hadoop.dll and hadoop.lib files requires no amendment and should compile without issue.
Building the WinUtils Solution with Visual Studio
Add Preprocessor Directives
On the winutils Poject Properties dialogue, choose your required Configuration. In the Configuration Properties | C/C++ | Preprocessor | Preprocessor Definitions select ‘Edit…’ to amend the values, as shown below:
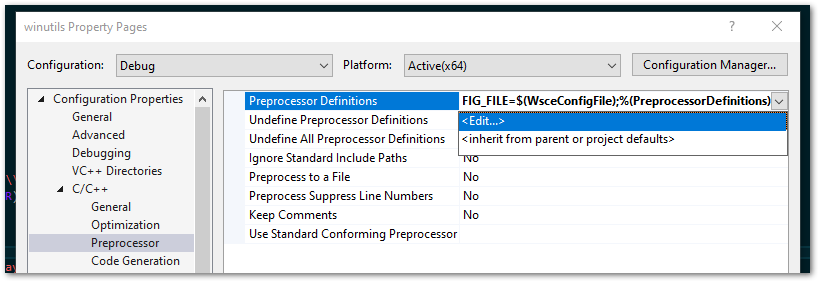
You’ll see the evaluated values in the second box. I’ve edited one below to show this taking effect. Notice that WSCE_CONFIG_FILE is still undefined as far as Visual Studio is concerned. This will also need to have a value as well as mentioned above.
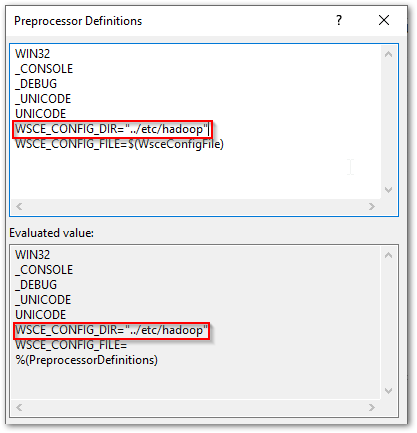
Do the same for the libwinutils project.
Issues Building on x64 Windows
By default, the original projects are configured to build against the x86 Windows platform. If you try and build using this on a x64 Windows machine, you will probably encounter the error below.

This can throw you off the scent a little as to the real issue here. You have the build tools installed as part of the Visual Studio setup for C++ projects, so why all the belly aching? Well, you’ll need to change the project configurations to build vs x64, as the build tools you have installed will be for this architecture.
If you are on x64 Windows, be sure to change the project configurations so that they build against the x64 rather than x86 platform, to avoid the issue mentioned above. This is done from Build | Configuration Manager… as shown below:
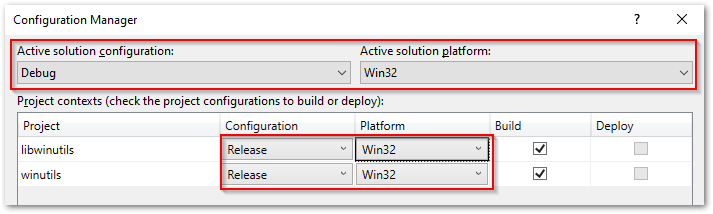
Build Your Solution
Right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B, and this will build first the libwinutils project (a dependency of winutils) and then the winutils project, to the output directories expected for your configuration.
Building the WinUtils Solution with MSBuild
Opening up a ‘Developer Command Prompt for Visual Studio’, you’ll have access to MSBuild from the command line. If you have added the path to MSBuild.exe to your ‘Path’ environment variable you will have access to this also from a regular command prompt. Navigate to your winutils solution directory.
As with the Visual Studio method, you’ll need to specify the correct platform if you are on x64, as it will default to an x86 build. Otherwise, you’ll get the same error as shown in the Visual Studio section above regarding missing build tools. It would be nice if MSBuild defaulted to use the same platform as the tooling for your installation. A simple parameter addition is all that is required to sort this.
In addition, add the parameters as defined in the Maven pom file , resulting in the MSBuild command as below:
rem output for the build will be to the winutils\bin directory MSBuild winutils.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\Winutils\ /p:WsceCOnfigDir="../etc/config" /p:WsceConfigFile="wsce-site.xml"
Execute this from the winutils solution directory to ensure the relative paths are as desired. You outputs will be built and output to the winutils\bin directory specified.
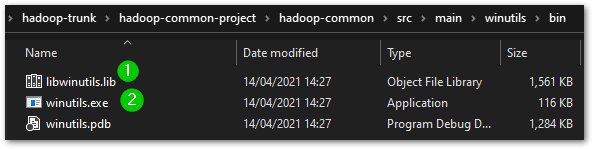
Building the Native Solution with Visual Studio
As mentioned, there are no code amendments required for the native.sln file that creates hadoop.dll and hadoop.lib. You will however need to change the configuration to x64 as necessary, as per ‘Issues Building on x64 Windows’ above. Once that is done, right-click the solution and action ‘Build Solution’, or use Ctrl+Shift+B and your code will be output to the respective debug or release folders.
Building the Native Solution with MSBuild
Follow the above ‘Building the WinUtils Solution with MSBuild’, navigating instead to the native solution directory and substituting the following MSBuild command.
rem output for the build will be to the native\bin directory MSBuild native.sln /nologo /p:Configuration=Release /p:Platform=x64 /p:OutDir=bin\ /p:IntermediateOutputPath=\native\"
You outputs will be built and output to the native\bin directory specified.
A Build of Our Very Own WinUtils for Spark
Well technically not really ‘ours’, as those nice dedicated Hadoop developers did all the real work, but anyway. So now you have a build of your own winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files for winutils from known source code. This ticks those security checkboxes nicely. Bring the trumpeters back in…yay! Oh, they’ve gone home, never mind, improvise. Woop woop, papapapapa etc. etc. Take a bow.
Using Your WinUtils Executable
Destination Directory
In order for Spark to use the WinUtils executable, you should create a local directory with a ‘\bin’ subdirectory as suggested below:
D:\Hadoop\winutils\bin
Copy the winutils.exe, libwinutils.lib, hadoop.dll and hadoop.lib files files generated earlier to this destination.
Environment Variables
HADOOP_HOME
You then need to add an environment variable ‘HADOOP_HOME’ for Spark to understand where to find the required Hadoop files. You can do this using the following powershell:
# Setting HADOOP_HOME System Environment Variable
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'D:\Hadoop\winutils', [System.EnvironmentVariableTarget]::Machine)
Note: This needs to be the name of the parent of the bin directory, with no trailing backslash.
As environment variables are initialised on startup of terminals, IDEs etc, any that are already open will need to be reopened in order to pick up our ‘HADOOP_HOME’.
Path
We’ll also need to add the path to the bin directory to our Path variable, if we want to invoke ‘winutils’ from the command line without using the full path to the .exe file.
# Append winutils.exe folder location to the System Path
[System.Environment]::SetEnvironmentVariable('Path', "${env:Path};D:\Hadoop\winutils\bin;", [System.EnvironmentVariableTarget]::Machine)
With that done we are all set to use this with our local Spark installation.
Signing Off…
Something of a diversion from the general world of data analytics this time, but for those who need to run Spark on Windows with no awkward questions about where that exe came from, this article should be of benefit. In the next post in this series we’ll look at setting up Spark locally, something that is not half as scary as it sounds. It is also at least twice as useful as you might initially think, maybe even three times. Till next time.


